Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.

“The best data isn’t always collected—it’s created.” Imagine training powerful AI models without ever collecting real user data—while maintaining accuracy, diversity, and privacy. Sounds like science fiction right? Synthetic data generation is turning this into reality.
In the era of AI-driven innovation, data serves as the foundation for advancements across various domains, including autonomous vehicles, medical diagnostics, and financial fraud detection. However, obtaining high-quality, diverse, and privacy-compliant AI data remains a critical challenge. Synthetic data generation offers a transformative solution by producing artificial yet highly realistic datasets, enabling the effective and ethical training of AI models.
Synthetic data refers to artificially generated data that mimics real-world data while ensuring privacy, security, and scalability. Unlike traditional data collected from real users or events, synthetic data is created through algorithms, simulations, and generative models like GANs (Generative Adversarial Networks) and Variational Autoencoders (VAEs).
A recent survey found that 48% of M&A professionals are now using AI in their due diligence processes, a substantial increase from just 20% in 2018, highlighting the growing recognition of AI’s potential to transform M&A practices.
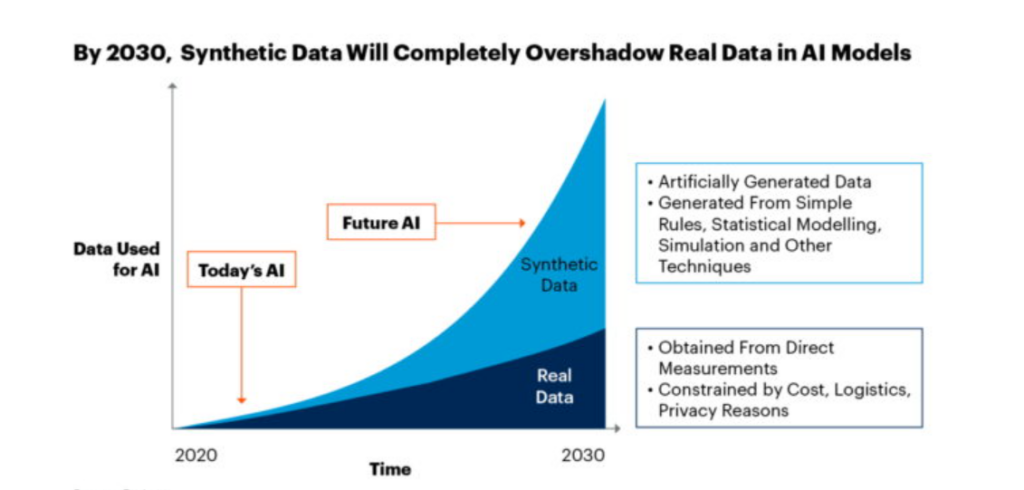
Source: Gartner
Why is Synthetic Data Important?
The benefits of synthetic data are broad and impactful. Here’s why it’s becoming indispensable in AI development:
Enhancing Privacy and Compliance: Synthetic data ensures GDPR and CCPA compliance by eliminating real user information, enabling secure AI model training.
Overcoming Data Scarcity: Industries like healthcare and finance benefit from synthetic data, which helps generate diverse, well-balanced datasets to compensate for limited real-world data.
Reducing Bias in AI Models: By enabling controlled dataset generation, synthetic data reduces societal biases, ensuring fairer AI outcomes across demographics and behaviors.
Scalability and Cost Efficiency: Collecting and labeling real-world data can be time-consuming and expensive. This is where synthetic data offers an efficient alternative by generating large-scale datasets with minimal cost.
Now, the question remains how to generate synthetic data?

Creating synthetic data is a highly specialized process that involves a variety of techniques to ensure AI-ready data for the success of your AI initiatives. Here are some of the most widely used methods:
- Rule-Based Simulation: This technique utilizes predefined rules to generate synthetic data that mirrors real-world patterns, where specific variables are manipulated to produce realistic data points.
- Statistical Methods: By analyzing the statistical properties of real datasets, synthetic data can be created to reflect the same trends and distributions, ensuring privacy by excluding personal information.
- Machine Learning Models: Advanced models such as GANs and Variational Autoencoders (VAEs) are trained on real data to identify complex patterns, enabling the generation of highly realistic synthetic data for AI model training.
- Large Language Models (LLMs): LLMs, like GPT, can be fine-tuned to generate structured textual data, making them valuable for applications in Natural Language Processing (NLP) and database simulations.
Real-World Applications of Synthetic Data
Now, if you’re wondering about where can we use this synthetic data in real-world scenarios, then let’s take you through few of the use cases for synthetic data that spans across various industries.
- Healthcare: Synthetic data enables medical researchers to train AI models with simulated patient information, ensuring privacy and compliance without exposing sensitive medical records.
- Finance: In the financial sector, synthetic data allows for the creation of transaction datasets that replicate real-world behaviors, supporting fraud detection models while safeguarding sensitive transaction data.
- Autonomous Vehicles: By generating a wide range of diverse driving scenarios, synthetic data helps train AI systems for autonomous vehicles, preparing them for any situation on the road.
- Cybersecurity: Synthetic data plays a key role in cybersecurity by enabling organizations to simulate attack scenarios and stress-test their security systems without compromising real, sensitive information.
But wait! No matter how promising synthetic data generation may sound, it does come with its set of challenges like any other technology. Here are a few that needs attention:
- Ensuring Realism: How do we know that synthetic data is truly useful? The synthetic data must maintain the statistical characteristics of real-world data for it to be effective. Without this, the AI models trained on this data might underperform.
- Avoiding Data Leakage: This is a big one—poorly generated synthetic data can still retain identifiable patterns from the original dataset, leading to inadvertent data leakage. Ensuring the integrity of the synthetic data is crucial.
- Regulatory Compliance: Data privacy laws like GDPR or HIPAA are strict. Organizations generating synthetic data must ensure that they adhere to these regulations, ensuring both privacy and compliance.
Additional Benefits and Applications of Synthetic Data Generation
- AI Model Enhancement: Synthetic data augments real datasets, addressing data limitations and imbalances. In image recognition, it enhances model robustness by introducing variations.
- Diverse Data Generation: It expands datasets by incorporating rare and edge cases, improving AI model generalization and accuracy.
- Edge Case Simulation: Synthetic data creates rare scenarios, crucial for autonomous vehicles and risk-sensitive applications.
- Federated Learning Integration: It enables secure AI training across decentralized systems without exposing sensitive data.
- Privacy-Preserving Personalization: Businesses can simulate user behavior to refine recommendations while maintaining privacy.
- Real-Time Data Simulation: Dynamically generated synthetic data supports AI in applications requiring continuous updates, such as stock market forecasting and IoT.
- Model Validation and Stress Testing: AI models can be evaluated under extreme conditions using synthetic test cases, ensuring resilience.
- Data Anonymization: By preserving statistical properties while removing identifiers, synthetic data enables privacy-compliant AI development.
- Hybrid Data Solutions: Combining synthetic and real data enhances reliability while ensuring compliance with privacy regulations.
- Unstructured Data Generation: Synthetic data extends beyond structured formats, producing realistic images, text, and audio for AI training.
The Evolving Landscape of Synthetic Data Generation

Source: Grand View Research
Looking ahead, synthetic data will continue to evolve, becoming more sophisticated as advancements in AI drive its capabilities. The potential for AI-powered simulation models is immense, offering increasingly accurate and dynamic datasets that closely replicate real-world scenarios. Additionally, the integration of federated learning will allow organizations to collaborate on model training while maintaining privacy, significantly enhancing the scalability and security of synthetic data generation. Meanwhile, differential privacy techniques will ensure that the generated data remains compliant with global privacy standards, protecting individual identities while preserving data utility. As these innovations progress, synthetic data will become an even more powerful tool, transforming industries by enabling more robust, secure, and efficient AI model training.
The Road Ahead: Privacy-Preserving Synthetic Data generation for Recommendation Systems
As privacy concerns continue to grow, especially regarding the collection and sharing of sensitive user data, synthetic data generation offers a crucial tool for ensuring that privacy standards are upheld without sacrificing the effectiveness of recommendation algorithms. Recommendation systems, particularly those based on collaborative filtering (CF), rely heavily on users’ historical interaction data—such as purchase histories, feedback, and behavioral patterns—to provide personalized suggestions. However, this data is inherently sensitive and poses privacy risks if shared with external organizations or stored insecurely, especially in public cloud environments.
Current privacy-preserving solutions typically address privacy concerns only during the model training and result collection phases. However, the risk of privacy leakage remains when user interaction data is shared directly with organizations or made publicly available. This gap underscores the need for a more comprehensive approach to privacy, which is where synthetic data generation comes into play. By leveraging synthetic data, organizations can create highly realistic datasets that simulate user behaviors and preferences without ever relying on real, sensitive data. This approach not only eliminates the risks of privacy violations but also allows for the continued development and training of effective recommendation models.
The key advantage of privacy-preserving synthetic data lies in its ability to generate datasets that mirror the nuances of user interactions, yet without revealing any personally identifiable information. For example, datasets can be crafted to simulate diverse user profiles, behaviors, and interactions based on controlled variables, ensuring that the resulting recommendations reflect a broad spectrum of user preferences. This capability helps mitigate biases in recommendation systems, making them more inclusive and representative of varied user demographics. By using synthetic data, organizations can continue to offer personalized experiences while maintaining strong privacy protections.
The integration of synthetic data generation in recommendation systems will become increasingly essential. As users demand greater control over their personal data and as privacy regulations tighten, businesses will need to adopt methods that preserve privacy without compromising on the quality of their services. Synthetic data generation provides a pathway to achieving this balance, allowing organizations to build effective, secure, and inclusive recommendation models. In turn, this will help foster greater user trust and compliance with privacy laws, ensuring that personalized recommendations remain an integral part of digital platforms without exposing users to unnecessary privacy risks.
Final Thoughts
As artificial intelligence continues to evolve, the need for high-quality, privacy-preserving data is becoming increasingly critical. Synthetic data presents a transformative solution to challenges related to data privacy, accessibility, and bias mitigation. Far from being a passing trend, it is emerging as an essential tool for fostering responsible, scalable, and efficient data-driven innovation.
The trajectory of AI, machine learning, and data science will largely depend on how seamlessly synthetic data can be integrated into existing workflows. By harnessing these advanced methodologies, organizations can unlock unprecedented opportunities while upholding the highest standards of ethical and regulatory compliance.
Is your industry prepared to embrace synthetic data as a catalyst for innovation? If not then Quinnox’s comprehensive suite of Gen AI and Data-Driven Intelligence services can help generate quality AI data to unlock limitless possibilities.
With iAM, every application becomes a node within a larger, interconnected system. The “intelligent” part isn’t merely about using AI to automate processes but about leveraging data insights to understand, predict, and improve the entire ecosystem’s functionality.
Consider the practical applications:
In the Infinite Game of application management, you can’t rely on tools designed for finite goals. You need a platform that understands the ongoing nature of application management and compounds value over time. Qinfinite is that platform that has helped businesses achieve some great success numbers as listed below:
1. Auto Discovery and Topology Mapping:
Qinfinite’s Auto Discovery continuously scans and maps your entire enterprise IT landscape, building a real-time topology of systems, applications, and their dependencies across business and IT domains. This rich understanding of the environment is captured in a Knowledge Graph, which serves as the foundation for making sense of observability data by providing vital context about upstream and downstream impacts.
2. Deep Data Analysis for Actionable Insights:
Qinfinite’s Deep Data Analysis goes beyond simply aggregating observability data. Using sophisticated AI/ML algorithms, it analyzes metrics, logs, traces, and events to detect patterns, anomalies, and correlations. By correlating this telemetry data with the Knowledge Graph, Qinfinite provides actionable insights into how incidents affect not only individual systems but also business outcomes. For example, it can pinpoint how an issue in one microservice may ripple through to other systems or impact critical business services.
3. Intelligent Incident Management: Turning Insights into Actions:
Qinfinite’s Intelligent Incident Management takes observability a step further by converting these actionable insights into automated actions. Once Deep Data Analysis surfaces insights and potential root causes, the platform offers AI-driven recommendations for remediation. But it doesn’t stop there, Qinfinite can automate the entire remediation process. From restarting services to adjusting resource allocations or reconfiguring infrastructure, the platform acts on insights autonomously, reducing the need for manual intervention and significantly speeding up recovery times.
By automating routine incident responses, Qinfinite not only shortens Mean Time to Resolution (MTTR) but also frees up IT teams to focus on strategic tasks, moving from reactive firefighting to proactive system optimization.
Did you know? According to a report by Forrester, companies using cloud-based testing environments have reduced their testing costs by up to 45% while improving test coverage by 30%.
Frequently Asked Questions (FAQs)
Synthetic data is artificially generated data that mimics real-world data while ensuring privacy, security, and scalability. It is important because it allows AI models to be trained without relying on sensitive real-world data, ensuring compliance with privacy regulations and reducing the risks of data breaches or leaks.
Privacy-preserving synthetic data generation refers to the process of creating artificial datasets that closely mimic real-world data while ensuring the protection of sensitive personal information. This method allows organizations to generate realistic data for AI and machine learning applications without using real user data, thus maintaining privacy and complying with data protection laws like GDPR and CCPA.
The goal of privacy-preserving synthetic data is to enable organizations to use realistic, high-quality data for AI model training and testing while ensuring that no sensitive personal information is exposed or misused. Here’s how it works:
Synthetic Data Creation: Instead of collecting real user data, synthetic data is generated using algorithms, simulations, or models such as GANs (Generative Adversarial Networks) or VAEs (Variational Autoencoders). These models learn patterns and relationships from real datasets and then produce new, artificial data that reflects the original data’s statistical characteristics but without exposing any personal or sensitive information.
Privacy Preservation: Since the synthetic data doesn’t involve real user data, it eliminates the risk of data leakage or breaches of personally identifiable information (PII). It can be used for AI training without violating privacy, thus ensuring compliance with data protection regulations.
Applications: Privacy-preserving synthetic data is particularly valuable in fields like healthcare, finance, autonomous vehicles, and cybersecurity, where data privacy is a significant concern. For example, medical research can use synthetic patient data to train AI models without using real patient records.
Synthetic data helps reduce bias by enabling controlled dataset generation, which ensures more balanced and diverse datasets. This approach allows AI models to train on data that represents a wider range of demographics and behaviors, leading to fairer outcomes across different groups.
Synthetic data is used in various industries, including healthcare (for training medical AI models without using sensitive patient data), finance (to create transaction datasets for fraud detection), autonomous vehicles (for simulating diverse driving scenarios), and cybersecurity (for testing security systems without exposing real information).
Some challenges include ensuring the realism of synthetic data to make it useful for AI model training, preventing data leakage where identifiable patterns might still exist, and complying with strict data privacy regulations like GDPR and HIPAA.
Synthetic data can simulate user behaviors and preferences without using real, sensitive data. This ensures privacy by eliminating risks of data leakage while still providing organizations with accurate datasets to develop and train recommendation systems that reflect diverse user profiles.