For most enterprises today, data isn’t the problem; turning it into trusted, usable insight at scale is. As per Statista, global data creation is projected to surpass 180 zettabytes by 2025, a huge jump from 2020 levels. At the same time, Gartner reports that 59% of organizations don’t formally measure data quality, and less than half of data and analytics leaders (44%) say their teams are effective at providing value to the business. Meanwhile, 61% of organizations are being forced to rethink their data and analytics operating model because of AI, underscoring how fragile many existing data foundations are.
This is the context in which data pipelines have moved from a technical nice-to-have to a strategic capability. Done well, they give enterprises a governed, observable and scalable way to move, transform, and deliver high-quality data, so AI initiatives, analytics programs, and critical business processes are powered by reliable pipelines instead of brittle point-to-point integrations.
What is a Data Pipeline?
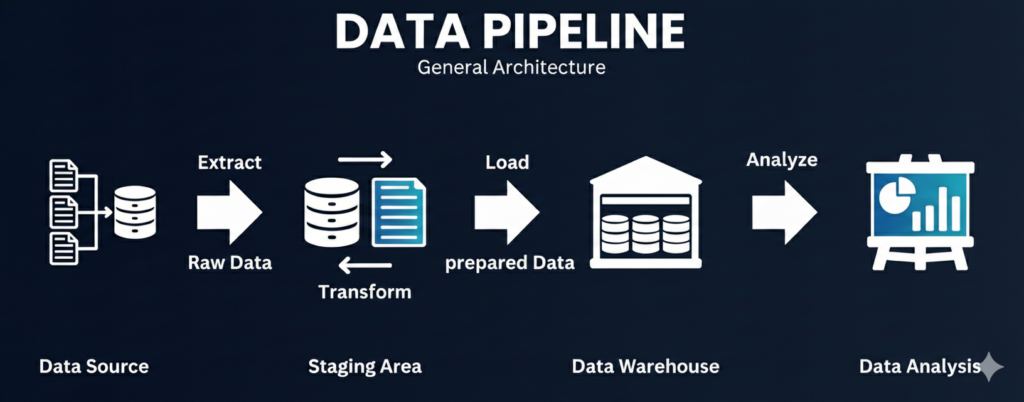
A data pipeline is an automated, end-to-end system that ingests data from multiple sources, processes it through transformation and validation steps, and delivers it to downstream destinations such as data lakes, data warehouses, lakehouses, operational databases, or real-time applications.
In modern enterprises, a data pipeline is far more than a simple “data movement mechanism.” It is the core operational layer that ensures:
- Data arrives on time – whether in batch, micro-batch, or streaming mode)
- Data is trustworthy through quality checks, schema enforcement, and lineage
- Data is governed and secure via access control, masking, auditability
- Data is production-ready for analytics, AI/ML, and business applications
A robust pipeline abstracts complexity so business teams can use data confidently without worrying about how it moved, transformed, or scaled behind the scenes.
-
-
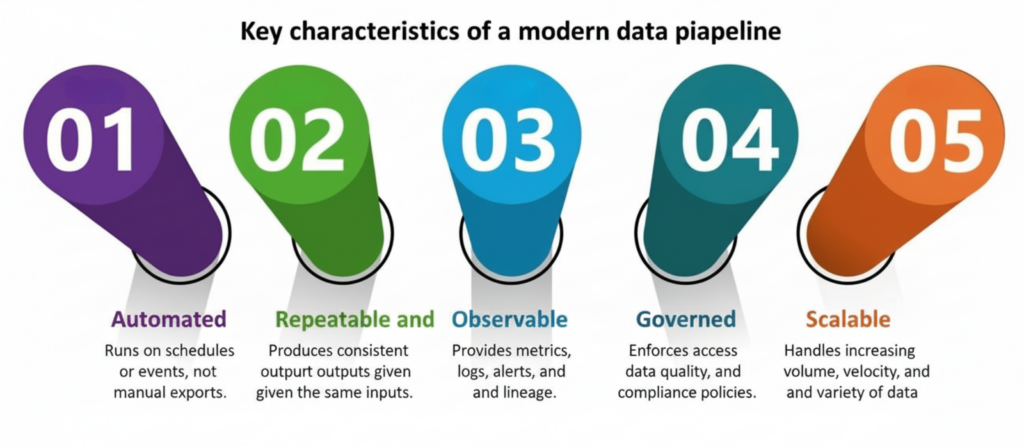
- Automated – Runs on schedules or events, not manual exports.
- Repeatable and reliable – Produces consistent outputs given the same inputs.
- Observable – Provides metrics, logs, alerts, and lineage.
- Governed – Enforces access control, data quality, and compliance policies.
- Scalable – Handles increasing volume, velocity, and variety of data.
-
Data Pipeline vs. Traditional ETL
Modern enterprises need more than scheduled data loads into a warehouse. As data supports real-time decisioning, AI models, and operational systems, traditional ETL has evolved into broader, more resilient data pipelines.
The table below highlights how classic ETL differs from modern data pipelines across the dimensions that matter most for scale, speed, and business impact.
| Dimension | Traditional ETL | Modern Data Pipeline |
|---|---|---|
| Primary Focus | Batch data movement for BI and reporting | End-to-end data delivery for analytics, AI, and operations |
| Latency | Batch-only (hours to days) | Batch, micro-batch, and real-time |
| Data Flow | One-way (source → warehouse) | Bi-directional, including reverse ETL |
| Use Cases | Historical dashboards | BI, personalization, fraud, ML, operational apps |
| Scalability | Rigid, infrastructure-bound | Elastic, cloud-native scaling |
| Governance & Trust | Limited, often manual | Embedded quality, lineage, and security |
Key Components of a Data Pipeline
A modern data pipeline is more than a linear flow of data; it’s a coordinated system of capabilities that ensure data moves reliably, securely, and in a business-ready state. To build pipelines that scale across an enterprise, it’s useful to think in terms of foundational components that work together to support ingestion, transformation, governance, and consumption.
Below is a clean breakdown of the core components that shape a resilient, production-grade data pipeline:
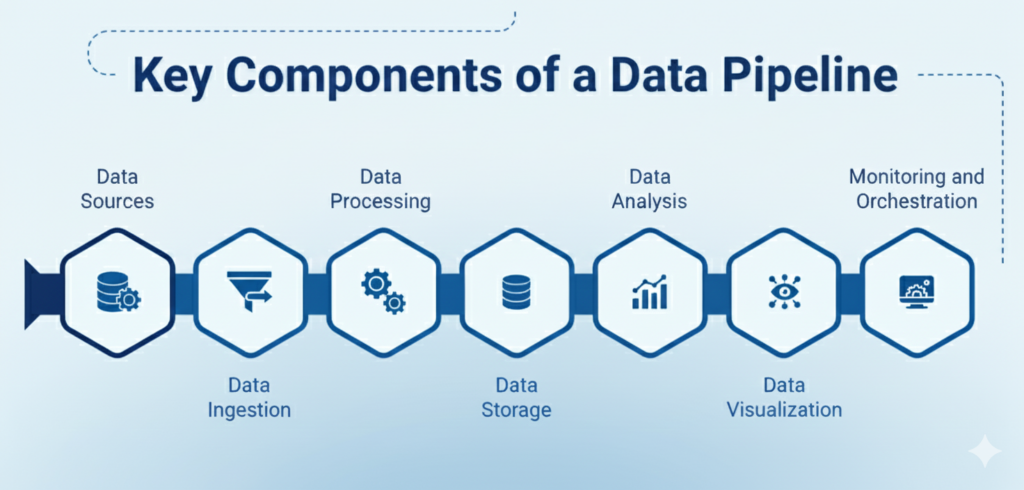
1. Data Sources
The origin of truth for your pipeline – transactional systems, SaaS applications, event streams, IoT devices, logs, files, and third-party datasets. A pipeline must accommodate diverse formats, frequencies, and data freshness needs.
2. Ingestion Layer
This layer includes batch ingestion, API-based extraction, streaming/event capture, and change data capture (CDC). At scale, the ingestion layer must manage schema drift, throttling, retries, and ensure minimal disruption to source systems.
3. Processing & Transformation
The engine room of the pipeline – Data is validated, cleaned, enriched, standardized, and reshaped to meet business requirements. Processing can occur via distributed engines (Spark, Flink), SQL-based ELT models, or cloud-native transformation services.
4. Storage & Data Layers
Where transformed data is persisted for downstream use – typically structured in layers such as raw, refined, and business-ready (often referred to as bronze, silver, and gold). Warehouses, lakes, and lakehouses all play a role depending on latency, structure, and analytics needs.
5. Orchestration & Workflow Management
This component coordinates the order, timing, and dependencies of jobs. It ensures pipelines run reliably, recover from failures, and meet SLAs. Orchestration governs how tasks connect, trigger, and scale across environments.
6. Data Quality & Validations
Quality is not an afterthought – Pipelines must include rules and checks for completeness, freshness, duplicates, anomalies, referential integrity, and schema consistency. These validations protect downstream analytics, models, and business processes.
7. Observability &Lineage
Observability and lineage form the foundation of data intelligence, enabling teams to troubleshoot issues faster, perform impact analysis with confidence, maintain audit readiness, and ensure that downstream analytics and AI systems can rely on trusted, verified data.
8. Governance & Security
Strong pipelines require embedded controls – access management, masking, classification, encryption, and audit logs. Effective data governance for AI ensures compliant, high-quality data feeds models responsibly while meeting standards like GDPR, HIPAA, and PCI-DSS.
9. Consumption Layer
The final delivery point where data becomes usable – This may include BI dashboards, machine learning pipelines, operational systems, product features, or external APIs. The consumption experience should be consistent, well-governed, and optimized for each user group.
Types of Data Pipelines
Different types of data pipelines exist because not every use case needs real-time data, and not every domain can tolerate stale data. Top-ranking resources usually slice them by latency, pattern, and topology.
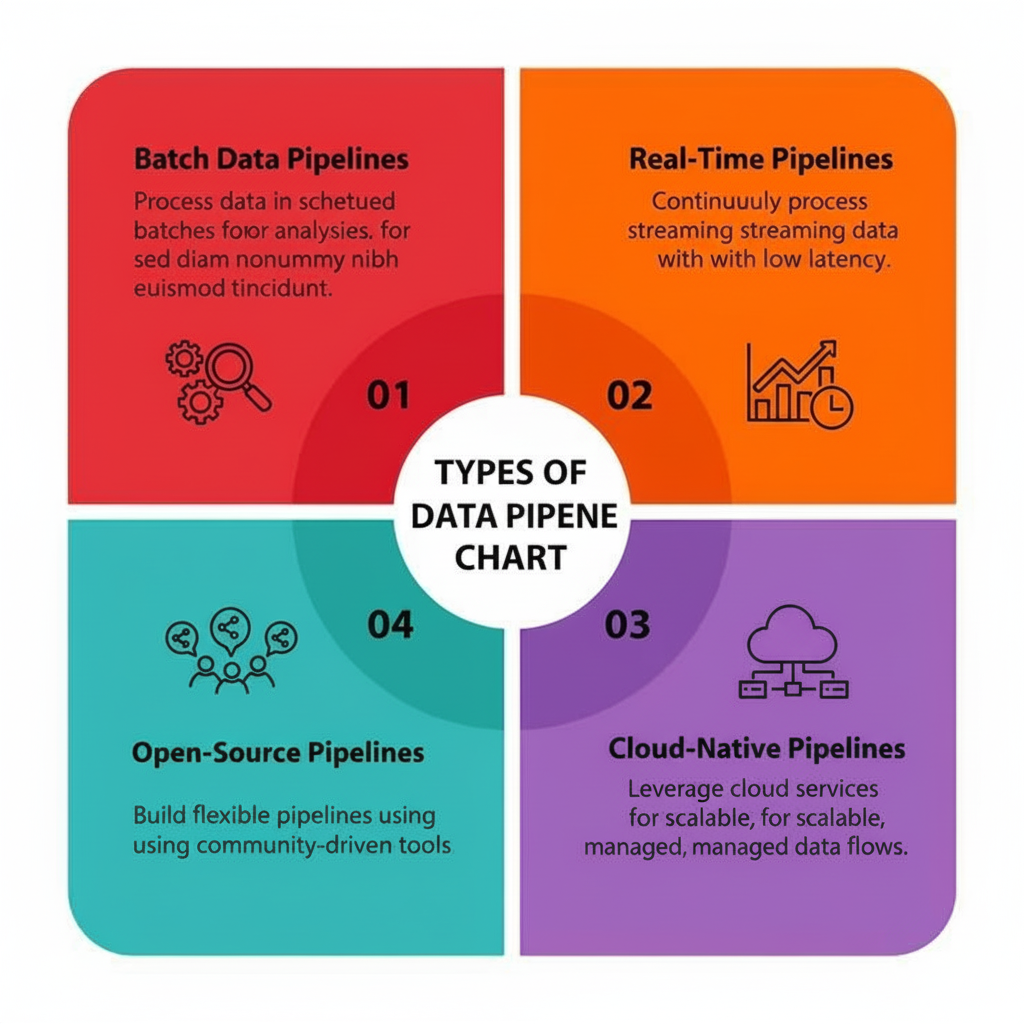
1. Batch Data Pipelines
Batch data pipelines process large volumes of data at scheduled intervals (hourly, daily, or weekly). They are ideal for financial reporting, reconciliations, historical analytics, and scenarios where real-time insights are not critical.
2. Real-Time / Streaming Data Pipelines
Real-time pipelines ingest and process data continuously with minimal latency. These pipelines power use cases such as fraud detection, personalization, monitoring, and event-driven decisioning where immediate action is required.
3. Cloud-Native Data Pipelines
Cloud-native pipelines are built to leverage elastic cloud infrastructure, separating compute from storage for scalability and cost efficiency. They enable rapid scaling, managed services, and seamless integration with modern analytics and AI platforms.
4. Open-Source Data Pipelines
Open-source pipelines are built using community-driven frameworks and tools, offering flexibility and deep customization. They are well-suited for organizations that need fine-grained control over architecture and are willing to manage operational complexity.
Best Practices for Building Data Pipelines
Many high-ranking articles focus heavily on best practices, especially around reliability, scalability, and governance.
Below are enterprise-grade best practices you should bake into your data pipeline strategy.
1. Start from Business Outcomes & SLAs
-
- Define who the pipeline serves (analysts, product teams, risk, marketing).
-
- Specify acceptable latency (real-time, hourly, daily).
-
- Agree on data quality and availability SLAs.
-
- Prioritize use cases based on business impact, not just technical interest.
2. Choose the Right Latency for Each Use Case
Not everything needs streaming. Over-architecting for real-time increases cost and complexity:
-
- Use batch for regulatory reports, period-end aggregations, and stable dimensions.
-
- Use micro-batch or streaming only where responsiveness is critical (fraud, personalization, operational monitoring).
3. Standardize Data Contracts & Schemas
-
- Treat schemas as contracts between producing and consuming teams.
-
- Document expectations around field types, nullability, allowed values.
-
- Use schema registries for event streams.
-
- Enforce backward-compatible changes or versioned schemas to avoid breaking downstream jobs.
4. Design for Reliability, Idempotency & Failure
-
- Make operations idempotent (safe to rerun without duplicating results).
-
- Implement dead-letter queues for problematic records.
-
- Use retries with exponential backoff.
-
- Define clear policies for late-arriving and out-of-order data.
5. Invest in Data Observability Early
-
- Monitor:
-
-
- Pipeline health (success/failure, run time, backlog).
- Data quality (freshness, completeness, distribution changes).
-
-
- Implement alerting when SLAs are at risk.
-
- Use lineage to accelerate impact analysis during incidents.
6. Embed Governance & Security
-
- Integrate a data catalog for discoverability.
-
- Classify sensitive fields and enforce masking/role-based access.
-
- Ensure all data is encrypted and access is auditable.
-
- Align policies with legal/compliance teams (GDPR, CCPA, industry regulations).
7. Prefer Modular, Decoupled Architectures
-
- Use pub/sub and event streams to decouple producers from consumers.
-
- Build reusable transformation layers rather than duplicated logic across pipelines.
-
- Encapsulate pipeline logic as code modules, not copy-pasted scripts.
8. Automate with CI/CD and Infrastructure-as-Code
-
- Treat pipeline definitions (DAGs, SQL models, configs) as code.
-
- Use CI/CD to run tests (unit, integration, data quality) on every change.
-
- Manage infrastructure with IaC tools (Terraform, CloudFormation, etc.).
9. Optimize for Cost and Performance
-
- Separate storage and compute where possible.
-
- Use tiered storage (hot vs. cold data).
-
- Right-size cluster resources and auto-scaling policies.
-
- Track cost per pipeline / per domain to avoid runaway spend.
Enterprise Use Cases for Data Pipelines
Top-ranking articles highlight a broad set of use cases; here we’ll focus on ones that resonate with enterprise IT and data leaders.
1. Customer 360 & Personalization
Consolidate customer interactions from CRM, web, mobile, and support into unified profiles:
- Real-time clickstream ingestion for behavioral analytics.
- Batch enrichment with demographic and transactional data.
- Activation via reverse ETL into marketing and sales platforms.
2. Fraud Detection & Risk Analytics
Financial institutions use streaming pipelines to:
- Ingest transactions in real time.
- Apply ML models and rule-based checks.
- Trigger alerts and automated actions when anomalies are detected.
3. IoT & Operational Monitoring
Manufacturing, logistics, and energy companies use pipelines to:
- Collect telemetry from sensors and devices.
- Monitor equipment for health and performance.
- Power predictive maintenance and supply chain optimization.
4. Regulatory & Compliance Reporting
Banks, insurers, and healthcare organizations need:
- Traceable, auditable data flows.
- Reproducible aggregations and reconciliations.
- Long-term historical storage for audits.
5. ML Feature Pipelines & MLOps
- Build feature stores feeding by batch and streaming pipelines.
- Keep features consistent between training and inference.
- Provide data freshness guarantees to ML teams.
6. Enterprise Observability & Security Analytics
- Aggregate logs, metrics, and traces from multiple systems.
- Detect anomalies and security incidents.
- Feed SIEM platforms and observability tools.
Data Pipeline Examples (With Architectures)
Let’s walk through some conceptual architectures that many leaders find useful as reference patterns.
Example 1: Modern Analytics Pipeline (Lakehouse + Medallion)
Goal: Enterprise-wide analytics & BI on trusted, governed data.
Architecture at a glance:
- Sources: ERP, CRM, core systems, SaaS tools, clickstream.
- Ingestion:
- Batch extraction from DBs and SaaS APIs into object storage.
- Streaming ingestion for web/mobile events.
- Storage layers:
- Bronze: Raw, append-only data.
- Silver: Cleaned, conformed tables with quality checks.
- Gold: Business-ready models for finance, sales, risk, etc.
- Transformations:
- Implemented via SQL/ELT with dbt or warehouse-native transformations.
- Consumption:
- BI dashboards (Power BI, Tableau, Looker).
- Self-service data marts.
- ML training datasets.
Why it works for enterprises: Clear separation of concerns, governance-friendly, and flexible enough to support both BI and ML.
Example 2: Real-Time Fraud Detection Pipeline
Goal: Detect and act on fraudulent events within seconds.
Architecture:
- Sources: Transaction systems, login events, user behavior streams.
- Ingestion:
-
- Events published into Kafka or a similar streaming platform.
- Processing:
-
- Stream processing engine (Flink/Spark Streaming) applies:
-
- Rule-based filters.
-
- ML models for anomaly detection.
- Storage & Serving:
-
- Real-time state stores (for session behavior).
-
- Warehouse/lakehouse for historical retraining and offline analytics.
- Downstream actions:
-
- Alerts to risk teams.
-
- Automated holds or step-up authentication.
Enterprise value: Reduced fraud losses, regulatory compliance, and better customer trust.
Example 3: Reverse ETL for Customer Activation
Goal: Operationalize insights from the data warehouse in frontline tools.
Architecture:
- Sources:
-
- Gold-layer customer tables in the warehouse (LTV, propensity scores, churn risk).
- Processing:
-
- Orchestrated jobs transform and validate outbound datasets.
- Delivery:
-
- Reverse ETL tool pushes the data into CRM, marketing automation, and support tools via APIs.
- Consumption:
-
- Sales reps see prioritized lead lists.
-
- Marketers trigger tailored campaigns.
-
- Support teams see risk flags and recommended actions.
Enterprise value: Closes the loop between analytics and action, driving measurable uplift in revenue and retention.
Challenges in Maintaining Data Pipelines
Building a data pipeline is easy. Sustaining it at an enterprise scale is where most organizations struggle. The hardest challenges are rarely caused by a single tool or technology choice – they emerge from ecosystem complexity, organizational silos, and constant change across data sources, teams, and business priorities.
Below are the challenges that consistently derail enterprise data pipelines and erode trust in data.
1. Data Quality & Trust
When data definitions differ across domains, confidence collapses. Silent pipeline failures lead to stale dashboards, conflicting KPIs, and leadership decisions based on incomplete or incorrect data. Without clear ownership, issues linger undetected – often discovered only after business impact has already occurred.
2. Schema Drift & Source Volatility
Upstream systems evolve continuously. APIs change, schemas drift, and business rules are updated without warning. Pipelines that are not designed for change break frequently, forcing teams into reactive firefighting rather than proactive improvement.
3. Operational Complexity
Many enterprises accumulate dozens or hundreds of one-off scripts and ad-hoc jobs over time. Without standardized orchestration, observability, and lineage, even simple failures become hard to diagnose. Incident triage slows down, SLAs are missed, and data teams spend more time fixing pipelines than building new capabilities.
4. Governance & Compliance
Shadow pipelines built outside approved platforms introduce uncontrolled data flows and access sprawl. In regulated industries, the absence of end-to-end lineage and audit trails makes it difficult to prove compliance, increasing regulatory and reputational risk.
5. Skill Gaps & Organizational Silos
There is a chronic shortage of experienced data engineers, while demand continues to rise. At the same time, misalignment between central data teams and domain teams leads to duplication, friction, and stalled initiatives. Without product thinking, pipelines become brittle projects rather than scalable platforms.
6. Cost Management
Poorly governed pipelines drive hidden costs – underutilized compute, redundant tooling, and long-term storage of unused data. Many organizations struggle to attribute costs to specific domains or use cases, making optimization difficult and cloud spend unpredictable.
The most successful organizations treat data pipelines as long-lived products, with clear ownership, roadmaps, and continuous improvement -not as one-off projects
Closing Perspective
As enterprises scale analytics, AI, and real-time decisioning, data pipelines have become foundational infrastructure, not optional plumbing. The organizations that succeed are those that treat pipelines as resilient, governed products built for change, not as one-off integrations.
This is where Quinnox adds differentiated value – helping enterprises move from fragile, script-driven pipelines to intelligent, observable, and AI-ready data pipeline ecosystems. By embedding quality, governance, and automation by design, Quinnox enables data pipelines that scale with business ambition and quietly power every critical decision.
Ready to modernize your data pipelines? Connect with our experts to assess your current data pipeline maturity and define a roadmap toward scalable, trusted, and AI-ready data foundations.
FAQs About Data Pipelines
ETL is a specific pattern (Extract–Transform–Load) often used for moving data into a warehouse. A data pipeline is a broader concept that can include ETL, ELT, streaming, reverse ETL, and more, and can feed both analytical and operational systems.
No. Real-time pipelines add complexity and cost. Use them where latency has real business impact (fraud detection, personalization, alerts). For reporting, historical analytics, and many finance use cases, batch or micro-batch is sufficient.
Most enterprises benefit from a hybrid approach:
-Use managed tools/ELT platforms for common integrations and quick wins.
-Build custom pipelines where you need deep control, unique processing, or specialized performance.
The goal is to minimize undifferentiated heavy lifting while retaining control where it matters most.
- Enforce encryption in transit and at rest.
- Use role-based access control and fine-grained permissions.
- Mask or tokenize sensitive fields.
- Maintain detailed audit logs and lineage.
- Align with corporate security and compliance policies from the start.
Define KPIs such as:
Data freshness and SLA adherence.
Pipeline success rate and mean time to recovery.
Number of incidents caused by data issues.
Business impact metrics (conversion uplift, fraud reduction, cost savings).
User adoption of data products powered by the pipelines.