Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
By 2032, the AI inference market will hit $255.2 billion – almost triple its 2024 size of $91.4 billion (Fortune Business Insights)? That means in less than a decade, inference – the quiet engine behind every real-world AI application – will drive the lion’s share of enterprise AI value.
But here’s the question:
- Is your organization prepared to scale inference beyond proof-of-concept projects?
- Can your infrastructure handle real-time, high-volume predictions without spiraling costs?
- And most importantly, are you set up to turn AI models into tangible business outcomes?
The truth is, while AI training gets all the spotlight, it’s inference that powers fraud detection in banking, real-time recommendations in e-commerce, predictive maintenance in manufacturing, and life-saving diagnostics in healthcare. Simply put, training teaches the model, but inference makes it useful.
In this blog, we’ll break down how AI inference works, the best practices to optimize it, the benefits it unlocks across industries, and the challenges enterprises must overcome to make it work at scale.
What is AI Inference?
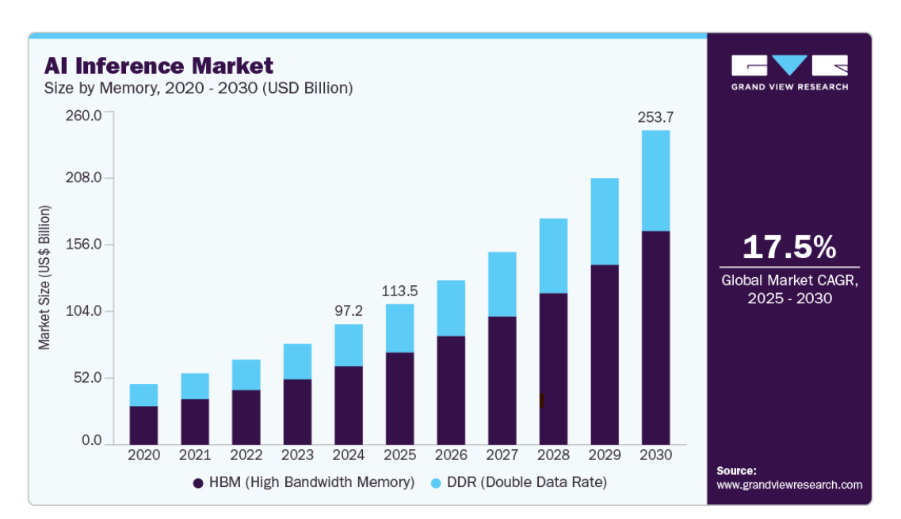
The global market for AI inference is expected to grow significantly valued at approximately USD 97.24 billion in 2024 and forecasted to surge to around USD 253.75 billion by 2030, reflecting a compound annual growth rate (CAGR) of 17.5% between 2025 and 2030.
To understand AI inference, it’s helpful to consider the two core stages of the machine learning lifecycle:
- Training phase – Models learn patterns from massive datasets, adjusting millions (or even billions) of parameters. This stage is computationally heavy and often run on specialized infrastructure.
- Inference phase – The trained model is deployed to make predictions on new, unseen data. This is where the model applies what it has learned to real-world inputs in real time or in batch mode.
AI inference is the execution phase of machine learning. It transforms AI from a theoretical capability into a business enabler, delivering the intelligence needed for fast, accurate decisions. Unlike training, which happens periodically, inference operates continuously – in production environments, on devices, or at the edge.
However, building efficient inference pipelines is not without challenges. Issues like latency, scalability, cost, and infrastructure optimization play a decisive role in determining how well AI performs in production.

How AI Inference Works
Getting AI inference to work well in real world systems involves a few key stages and architectural decisions. Below is a typical breakdown of how inference pipelines are structured and deployed.
1. Data Input & Pre-processing
Inference starts when new, unseen data arrives – for example, a user query, a transaction record, a camera image, a sensor reading, or streaming IoT metrics. Before feeding that input to a model, the data usually goes through pre-processing steps such as:
- Formatting and normalization (e.g. scaling numerical values, tokenizing text, resizing images)
- Feature extraction or transformation (turning raw input into the structured features the model expects)
- Caching or rapid lookup of auxiliary data (e.g. user profile features, previously computed embedding, or real-time event history)
- Handling missing values or applying fall-back heuristics if real-time data isn’t available
This pre-processing stage is critical to ensure the model sees input in the right shape, scale, and context, minimizing surprises or input mismatches.
2. Model Selection & Optimization
Once the input is ready, the system selects a trained model to run inference. Key decisions here include:
- Which version of the model? Often systems maintain multiple variants – for example, a large, highly accurate model for batch or offline inference, and a smaller, faster “lite” variant for real-time, low-latency inference.
- Optimized model format. Depending on latency, throughput, or resource constraints, the model might be quantized (e.g., 8-bit integer weights), pruned (removing weak connections), or compiled into a runtime optimized for inference hardware (e.g., an ONNX-compatible format, a TensorRT engine, or a TFLite binary).
- Hardware-aware tuning. The model might be adapted or converted to run well on the target hardware – CPUs, GPUs, TPUs, FPGA/ASIC inference chips, or edge accelerators. Oracle, for instance, emphasizes that architecture matching (and efficient use of GPU clusters) can greatly accelerate generative AI inference.
3. Inference Execution
With a clean input and a tuned model, the actual inference step proceeds:
- The system feeds the pre-processed input through the model, computing activations and final outputs (e.g., class probabilities, embedding vectors, score distributions, or generated text).
- Depending on the setup, inference may happen synchronously (real-time/online inference) or asynchronously (batch or streaming inference). Oracle distinguishes these modes:
- Online inference responds immediately to a request or event, requiring tight latency constraints.
- Batch inference processes large batches of data at scheduled intervals – optimizing for throughput and cost, rather than ultra-low latency.
- Streaming inference is a hybrid or continuous-processing mode, where data flows in as a stream and predictions flow out without strict “jobs” or “requests.” Think sensor streams, continuous logs, or IoT pipelines. Depending on latency and compute constraints, the system may use batching, caching, or dynamic dispatch strategies to balance throughput with responsiveness (e.g., grouping requests together or prioritizing “hot” fast-path routes).
4. Post-Processing & Decision Logic
After the raw model output is produced, the system typically applies post-processing and wraps that output with business logic:
- Applying decision thresholds, fallback rules or safety checks (e.g., “if confidence < X then defer to human review”)
- Transforming embeddings or probabilities into actionable formats (e.g., ranking top-k recommendations, converting scores into risk metrics, formatting responses for user-facing apps)
- Logging or storing inference results for downstream consumption (caching results, storing predictions in a database or feature store, feeding them to dashboards or APIs)
- Triggering follow-up actions or workflows (e.g. flagging a transaction for fraud investigation, sending a product recommendation back to a UI, issuing a maintenance alert, or responding in a chatbot)
5. Monitoring, Feedback & Adaptation
Finally, inference systems don’t just “fire and forget.” Production-grade inference pipelines often include:
- Real-time monitoring and observability: tracking latency, throughput, error rates, and input/output distributions, to detect bottlenecks or anomalies
- Logging and feedback capture: where the system records actual outcomes — e.g. whether a predicted fraud alert turned out to be genuine, whether a recommendation was clicked, or whether a diagnostic prediction matched ground truth
- Adaptive retraining or model switching: If feedback suggests that the data distribution has shifted, or that prediction accuracy is degrading over time, the system can route traffic to a newer or more robust model, or trigger retraining of the production model
- Dynamic scaling and optimization: Depending on load and sensitivity (especially in real-time inference), the pipeline may dynamically spin up more model replicas, degrade to simpler fallback models under load, or shift workloads to cheaper/off-peak compute resources
Best Practices for AI Inference Optimization
Scaling inference successfully requires more than just deploying a trained model – it demands deliberate choices around performance, cost, governance, and trust.
Here’s a deeper look at the best practices enterprises should adopt:
1. Set Clear Objectives
Before optimizing, you need to know what “good” looks like. Is your priority ultra-low latency (e.g., fraud detection in payments), high throughput (e.g., batch processing millions of records), or cost efficiency (e.g., inference on edge devices)?
Tie these goals directly to business KPIs:
- A bank might set a goal of detecting 99% of fraud attempts under 200 milliseconds.
- A retailer may prioritize recommendation freshness with sub-second updates to product feeds.
Without measurable objectives, optimization becomes guesswork.
2. Optimize the Model
Large, unoptimized models often lead to ballooning costs and latency. Techniques like:
- Quantization – Reducing numerical precision (e.g., from 32-bit floats to 8-bit integers) without major accuracy loss, cutting memory and compute requirements.
- Pruning – Removing redundant or low-weight connections from neural networks, shrinking model size while keeping accuracy.
- Knowledge Distillation – Training a smaller “student” model to mimic a larger “teacher” model’s output, retaining accuracy but reducing inference time.
3. Match Infrastructure to Workload
Inference isn’t one-size-fits-all. Different workloads demand different hardware:
- CPUs – Suitable for lightweight, occasional inference (e.g., batch jobs or small APIs).
- GPUs/TPUs – Handle high-throughput, parallel workloads like image recognition or large LLM queries.
- Edge accelerators (ASICs, FPGAs) – Run inference closer to data sources, minimizing latency in IoT or robotics.
Choosing the wrong infrastructure can double costs or create performance bottlenecks. For instance, using GPUs for low-volume workloads wastes money, while running a heavy LLM on CPUs could cause unacceptable lag.
4. Leverage Efficiency Techniques
Even with optimized models, efficiency at scale depends on how requests are processed:
- Batching – Grouping multiple inference requests together reduces compute overhead.
- Caching – Storing recent or repetitive results avoids recomputation (e.g., autocomplete suggestions).
- Request shaping – Routing requests based on priority (e.g., critical alerts get processed before routine queries).
When applied systematically, these techniques can boost throughput by 30–50% while keeping latency under control.
5. Monitor Continuously
AI inference pipelines can degrade over time due to model drift, infrastructure overloads, or shifts in user behavior. Continuous monitoring is critical to avoid silent failures.
Key strategies include:
- Observability dashboards tracking latency, throughput, error rates.
- Canary rollouts deploying new models to a small fraction of traffic before scaling broadly.
- Shadow testing is running new models alongside existing ones for comparison without user exposure.
6. Ensure Transparency & Trust
As inference powers decisions in regulated and high-stakes industries, explainability and governance are no longer optional. Enterprises should:
- Integrate explainable AI (XAI) methods to show how predictions are made.
- Build fallback mechanisms (e.g., human review for low-confidence predictions).
- Maintain audit trails to satisfy compliance and governance requirements.
Transparent inference pipelines not only build trust with stakeholders but also help detect bias and systemic errors early.
Taken together, these best practices don’t just optimize performance – they turn inference from a technical task into a strategic advantage, enabling enterprises to scale AI confidently while balancing speed, cost, and trust.
Benefits of AI Inference
AI inference unlocks the real-world value of trained models, enabling organizations to make faster, smarter, and more scalable decisions. While effectiveness depends on robust, relevant datasets, the benefits span industries and use cases:
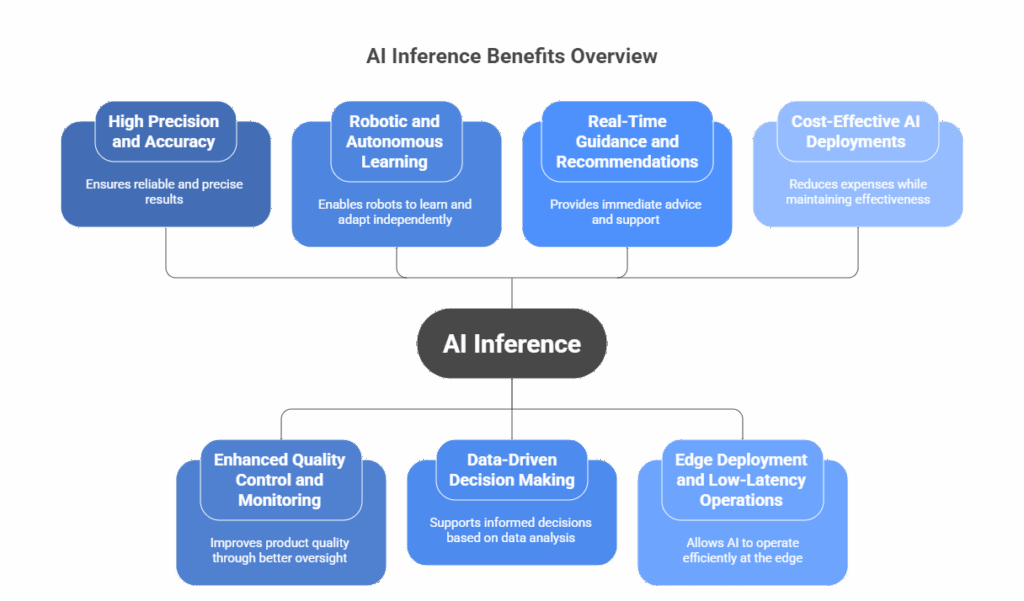
1. High Precision and Accuracy
Modern AI models deliver increasingly precise predictions. For instance, large language models (LLMs) can generate text that mimics an author’s tone, while AI in creative domains can select colors, styles, or composition to convey specific moods or artistic intent.
2. Enhanced Quality Control and Monitoring
AI inference supports real-time monitoring of complex systems. From industrial equipment health to environmental quality checks, inference models detect anomalies and enable proactive maintenance or interventions.
3. Robotic and Autonomous Learning
Robots and autonomous systems leverage inference to make informed decisions in dynamic environments. Driverless vehicles, for example, use AI inference to interpret traffic patterns, obey rules, and navigate safely, enhancing operational reliability.
4. Data-Driven Decision Making
Inference reduces the need for manual input by learning from historical data. Applications include agricultural monitoring to detect crop issues, financial systems to identify fraud, and healthcare or aviation to minimize human error in high-stakes processes.
5. Real-Time Guidance and Recommendations
AI inference can synthesize complex datasets to provide actionable insights. Investment advice, operational recommendations, and risk detection are all accelerated by models that understand nuance and context.
6. Edge Deployment and Low-Latency Operations
Running AI inference at the edge allows real-time predictions without sending data to centralized servers. This capability is critical for applications like warehouse management, autonomous vehicles, or any scenario requiring millisecond-scale responsiveness.
7. Cost-Effective AI Deployment
Optimized inference reduces compute and infrastructure costs by running models efficiently, choosing the right hardware, and minimizing unnecessary resource usage. This allows enterprises to scale AI widely without spiraling expenses.
Key Challenges in AI Inference
Deploying AI models for inference in real-world environments is more than just running trained models – it comes with a unique set of challenges spanning data, models, infrastructure, and organizational readiness.
1. Data Quality and Preparation
- Poor-quality or misformatted data leads to inaccurate predictions – “garbage in, garbage out” remains true.
- Ensuring that datasets are clean, relevant, and representative of real-world scenarios is critical to reliable inference outcomes.
2. Model Complexity
- Inference models range from simple (e.g., recognizing objects in images) to highly complex (e.g., detecting medical anomalies or financial fraud).
- More complex models require larger datasets, more compute resources, and careful selection or design to match business requirements.
3. Hardware and Resource Constraints
- AI inference often demands specialized hardware: GPUs, TPUs, FPGAs, or ASICs, along with high CPU memory and fast networks.
- Scaling inference for real-time or high-throughput workloads requires balancing resources and cost, particularly when deploying multiple models in production.
4. Latency, Scalability, and Cost
- Maintaining low-latency responses for real-time applications is challenging as models and data grow in size.
- Scaling inference pipelines without ballooning infrastructure costs requires optimization in batching, caching, and hardware utilization.
5. Interpretability and Explainability
- As models become more sophisticated, understanding how predictions are generated becomes harder.
- Explainable AI is increasingly essential for regulatory compliance, bias detection, and stakeholder trust.
6. Regulatory Compliance and Governance
- Organizations must address evolving regulations around privacy, security, and AI ethics.
- Inference pipelines should include robust reporting, auditability, and safeguards to meet compliance requirements.
7. Talent Shortage
- Expertise in designing, deploying, and optimizing inference pipelines is scarce.
- Recruiting or training personnel capable of managing AI inference at scale remains a significant organizational challenge.
Conclusion
AI inference has quietly become the engine that powers today’s intelligent experiences – from personalized recommendations and fraud detection to autonomous systems and real-time decision-making. While model training often gets the spotlight, it’s inference that brings AI to life in production, turning complex computations into practical, scalable outcomes.
This is where QAI Studio comes into play. By offering a structured platform for experimenting, testing, and deploying AI use cases, it enables organizations to move beyond experimentation and achieve production-scale inference. Teams can optimize models for efficiency, simulate deployment scenarios, and ensure governance – all while reducing the time from concept to outcome.
As businesses look to scale AI and data services, inference will remain the defining factor that separates proof-of-concept projects from enterprise-grade success stories. With platforms like QAI Studio, enterprises can seamlessly harness the power of AI inference and translate it into tangible business outcomes – driving faster decisions, smarter operations, and sustainable innovation.
FAQs Related to AI Inference
AI inference is the stage where a trained machine learning model is put to work, using its learned knowledge to make predictions or decisions on new data. While training teaches the model to recognize patterns, inference is where it applies that learning in the real world – for example, flagging fraudulent transactions, recommending a product, or analyzing medical images.
In practice, AI inference takes input data – such as text, images, or sensor readings – and runs it through a deployed model to generate an output. This can mean detecting tumors in healthcare scans, personalizing shopping experiences with product recommendations, analyzing financial transactions for fraud in banking, or spotting defects on manufacturing lines. The process enables businesses to act quickly and intelligently based on live data.
Organizations that adopt AI inference solutions can make faster, more accurate decisions, automate time-consuming tasks, and scale operations efficiently. Real-time predictions help cut costs, improve customer experiences through personalization, and unlock competitive advantages. Studies show that companies scaling AI effectively often report double-digit improvements in growth and operational efficiency.
Scaling inference is complex because it requires balancing speed, cost, and reliability. Enterprises often struggle with ensuring low-latency predictions, managing the high costs of GPUs or TPUs, and optimizing large models for production use. Integrating inference into existing systems and monitoring model performance as data evolves add further challenges. On top of this, organizations must ensure transparency and fairness in predictions to meet governance and compliance requirements.