Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
In a world where businesses operate at lightning speed, decisions are made in milliseconds, and machines predict customer needs before they even arise. This is the reality AI infrastructure is unlocking today. With 81% of executives prioritizing AI adoption, it’s clear that AI is no longer a futuristic vision, but it’s the backbone of modern enterprises. (Flexential Report)
Take Amazon for example – its AI-powered supply chain optimizes inventory management, reducing delivery delays by 30% and saving billions annually. Meanwhile, JPMorgan Chase employs AI-driven fraud detection to analyze 5,000+ variables per transaction, slashing fraudulent losses by 40%.
But here’s the challenge – 44% of organizations struggle with outdated IT infrastructure, limiting their ability to scale up AI solutions. Without robust computing power, seamless networking, and scalable storage, AI initiatives face bottlenecks and inefficiencies.
So, how can businesses build an AI infrastructure that delivers speed, agility, and accuracy? In this blog, we explore key components, best practices, and implementation strategies to help companies harness AI’s full potential.
Before you invest in AI infrastructure, validate the use case
80% of AI projects stall at the prototype stage. Our AI PoC Roadmap gives you a structured framework to test feasibility, assess data readiness, and build a business case before committing to infrastructure spend. Download the AI PoC Roadmap →
A recent survey found that 48% of M&A professionals are now using AI in their due diligence processes, a substantial increase from just 20% in 2018, highlighting the growing recognition of AI’s potential to transform M&A practices.
A Deep Dive into AI Infrastructure
AI infrastructure is the foundation that supports artificial intelligence applications, enabling them to process vast amounts of data efficiently. It integrates hardware, software, networking, and data management solutions to optimize AI workloads, ensuring scalability, speed, and compliance.
A well-structured AI infrastructure ensures seamless data flow for AI models, efficient computing power to process complex algorithms, scalable solutions for handling increasing AI demands, and secure and compliant frameworks for AI governance.
With 90% of enterprises deploying generative AI, the demand for reliable AI infrastructure is skyrocketing, pushing organizations to upgrade their capabilities.
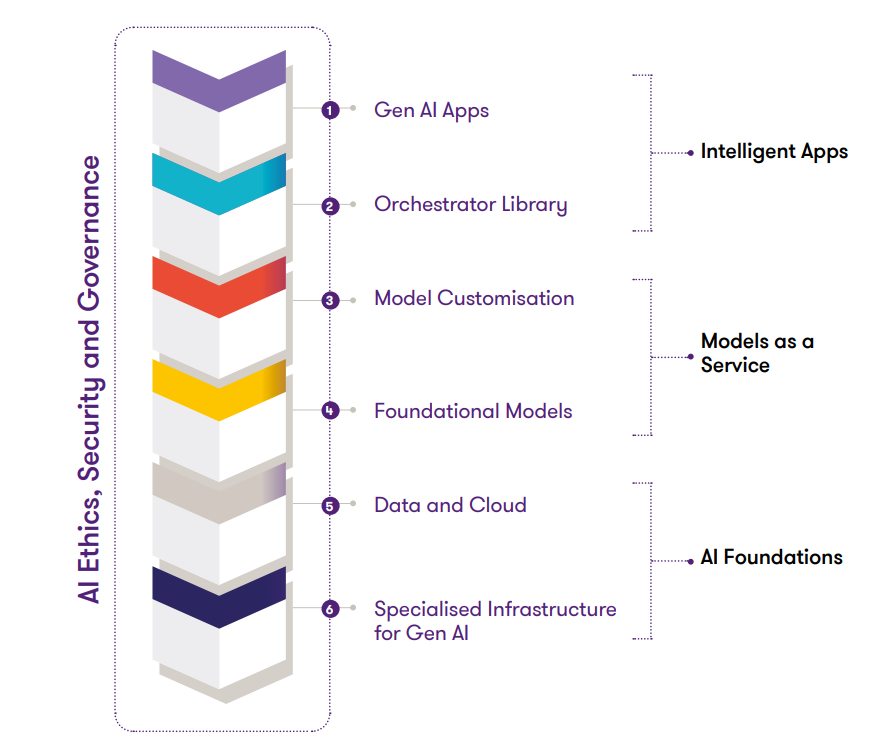
How AI Infrastructure Works
AI infrastructure operates in a systematic manner to facilitate the lifecycle of AI models – from training to deployment. Here’s how it works:
1. Data Acquisition & Storage
- AI models require diverse datasets, stored in structured or unstructured formats using databases, data lakes, and cloud storage.
- High-performance storage solutions ensure rapid access to large datasets, reducing latency in model training.
2. Preprocessing & Transformation
- Raw data undergoes cleaning, feature extraction, and transformation to enhance usability.
- AI frameworks integrate automated data pipelines for seamless preprocessing.
3. Computational Processing
- AI workloads require high computational power, often relying on GPUs, TPUs, or distributed computing environments.
- Parallel processing enables efficient handling of deep learning models.
4. Model Training & Optimization
- AI models are trained using algorithms and neural networks, optimizing parameters for accurate predictions.
- Continuous monitoring refines model performance, reducing bias and improving accuracy.
5. Deployment & Inference
- Once trained, models are deployed in production environments, integrated into applications or APIs.
- AI infrastructure ensures real-time inference capabilities, making intelligent decisions on incoming data.
6. Security & Compliance
- AI frameworks adhere to industry regulations (GDPR, HIPAA) and implement encryption, access controls, and ethical AI guidelines to prevent data breaches and bias.
Key Components of Modern AI Infrastructure
Building a high-performance AI infrastructure is like assembling a symphony of specialized tools and technologies—each playing a distinct role to ensure data flows seamlessly, models train faster, and predictions are served reliably.
Here’s a deep dive into the foundational components that power enterprise-grade AI systems:
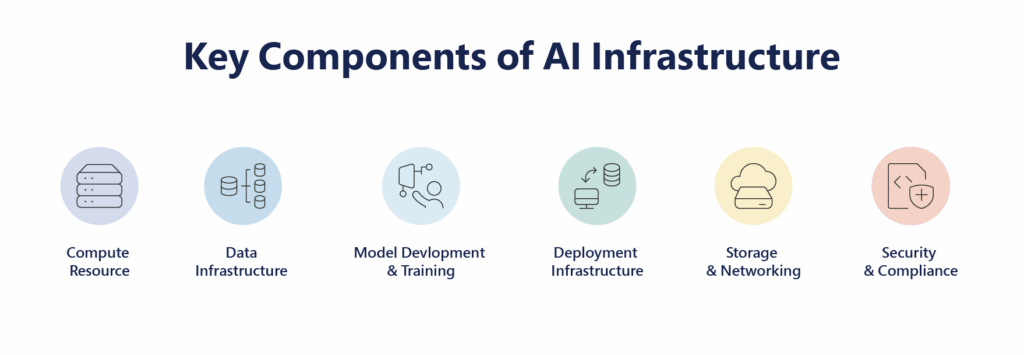
1. Compute Resources (CPUs, GPUs, TPUs)
AI workloads, especially deep learning – demand high computational power to process vast datasets efficiently. The right compute architecture can reduce model training time from weeks to hours, enabling faster AI innovation.
- GPUs (Graphics Processing Units) are the gold standard for AI training due to their parallel computing ability. A single high-end NVIDIA A100 GPU can deliver up to 20x faster performance than a CPU for AI tasks.
- TPUs (Tensor Processing Units), developed by Google, are designed specifically for machine learning and excel at matrix-heavy operations. Google uses TPUs to power products like Google Translate and Gmail’s smart reply.
- Edge processors are compact compute units embedded in IoT devices or autonomous systems. For example, Tesla’s Full Self-Driving computer leverages edge AI to make real-time driving decisions without depending on cloud latency.

2. Data Infrastructure (Lakes, Pipelines, Warehouses)
Without a robust data foundation, AI models lack context and accuracy. AI infrastructure must support scalable data storage, processing, and accessibility.
- Data Lakes for storing unstructured and semi-structured data.
- Data Warehouses for structured, analytics-ready data.
- ETL/ELT Pipelines for data transformation and enrichment.
- Real-Time Streaming for time-sensitive data.
- Metadata & Lineage Tools for data tracking and governance.
According to McKinsey, companies investing in AI-powered data infrastructure see 2.5x higher returns on AI initiatives
For example, a retail company using AI to recommend products needs its customer purchase history, browsing behavior, and inventory data all flowing smoothly into its model. Without a solid data infrastructure, AI insights are often inaccurate or delayed
3. Model Development & Training Environments
Building and training AI models requires sophisticated development environments that enable collaboration, experimentation, and performance tracking. Machine learning frameworks offer libraries and modules for creating a wide range of AI models. These frameworks are supported by development tools which provide interactive environments where data scientists can iterate quickly and visualize results in real time.
As model complexity grows, so does the need for distributed training environments. For instance, OpenAI trained GPT-4 using distributed compute clusters running thousands of GPUs in parallel, an approach that would be infeasible without optimized training orchestration.
According to Stanford AI Index Research, AI model training time has been reduced by 80% in the last five years due to advancements in distributed computing.
4. Deployment Infrastructure (Inference Engines + CI/CD for AI)
After a model is built, it needs to be deployed – meaning it must be made available to real users or systems to make decisions in real-time. This is where deployment infrastructure comes in. It allows teams to take their models and embed them into applications or devices where they can generate predictions or insights on demand.
Core Components include:
- Model Serving Platforms
- Model Versioning & Rollback that ensures accuracy and adaptability
- API Gateways which expose inference endpoints for applications
- CI/CD Pipelines for MLOps
According to Gartner, AI inference workloads account for 60% of cloud computing costs for enterprises
5. Storage & Networking
AI workloads demand high I/O throughput and reliable data movement – especially during model training and inference.
- High-Performance Storage: NVMe SSDs and distributed file systems ensure low latency and high bandwidth.
- High-Speed Networking: Technologies like InfiniBand and 5G (for edge use cases) reduce latency and enhance model training times.
- Hybrid/Multi-Cloud Architecture: Flexibility to move and access data across on-prem, cloud, and edge environments. This is especially critical for multinational enterprises with data residency laws.
For Instance, AI-powered content recommendation systems (Netflix, YouTube) rely on real-time data pipelines and high-throughput storage.
6. Governance, Security & Compliance
AI systems often touch sensitive or regulated data. Ensuring secure access, fairness, and compliance is essential to avoid reputational or legal risks.

Key governance capabilities:
- Encryption: Both at-rest and in-transit to protect data integrity
- Access Control: Role-based access (RBAC), audit logs, and authentication
- Bias & Fairness Audits: Regular evaluation of models for bias (gender, race, etc.)
- Explainability Tools: To provide transparency and traceability in model decisions
- Compliance Frameworks: GDPR, HIPAA, ISO 27001 must be embedded into infrastructure design
Together, these components create a scalable, flexible, and resilient environment capable of supporting sophisticated AI applications across industries.
CTA: Related Content: Navigating AI Governance: The Imperative of Ethical and Responsible AI
GPU vs TPU vs CPU: Choosing the Right Compute for Your AI Workloads
Selecting the right compute architecture is one of the most important decisions when designing modern AI infrastructure. The choice between CPUs, GPUs, and TPUs directly affects model training speed, inference latency, scalability, operational cost, and energy efficiency. While all three processors can execute AI workloads, they are built for very different purposes and perform best under different conditions.
| Compute Type | Best For | Key Strength | Limitation |
|---|---|---|---|
| CPU | General computing, preprocessing, lightweight inference | Flexibility and compatibility | Limited parallel processing |
| GPU | Deep learning training and inference | Massive parallel computation | Higher power and infrastructure costs |
| TPU | Large-scale AI optimization | High tensor processing efficiency | Less flexible ecosystem |
CPUs: Flexible and Reliable for General-Purpose AI Tasks
Central Processing Units (CPUs) remain the backbone of traditional computing environments. They are designed to handle a wide variety of operations sequentially and are highly effective for control-heavy workloads, data preprocessing, lightweight inference, and orchestration tasks.
For organizations beginning their AI adoption journey, CPUs are often the most accessible option because they are already integrated into existing infrastructure. They also work well for smaller machine learning models that do not require extensive parallel computation.
Key advantages of CPUs include:
- Strong performance for sequential processing
- Broad software compatibility
- Lower infrastructure complexity
- Efficient execution of preprocessing and ETL pipelines
- Suitable for edge devices and low-scale inference
GPUs: The Standard for Deep Learning Acceleration
Graphics Processing Units (GPUs) have become the dominant compute platform for AI training and high-performance inference. Unlike CPUs, GPUs contain thousands of smaller cores capable of executing parallel operations simultaneously. This architecture makes them exceptionally effective for deep learning workloads such as computer vision, natural language processing, recommendation systems, and generative AI models.
Modern AI frameworks are heavily optimized for GPU acceleration, allowing organizations to significantly reduce training time and improve throughput.
GPUs are particularly valuable for:
- Training large language models (LLMs)
- Real-time inference systems
- Image and video processing
- Distributed deep learning
- High-volume AI experimentation
Another major advantage of GPUs is ecosystem maturity. Most AI development tools, libraries, and cloud AI services are designed with GPU compatibility in mind, making deployment and scaling relatively straightforward.
Despite their performance benefits, GPUs can introduce higher infrastructure costs and power consumption. Organizations must also account for GPU allocation, memory optimization, and cooling requirements in production environments.
TPUs: Specialized Hardware for Large-Scale AI Optimization
Tensor Processing Units (TPUs) are specialized AI accelerators developed specifically for machine learning workloads. They are optimized for tensor operations and are particularly effective for large-scale neural network training and inference.
TPUs excel in environments where workloads are highly standardized and heavily dependent on tensor computations. Their architecture is designed to maximize throughput while minimizing training time for large models.
Common TPU use cases include:
- Massive-scale transformer model training
- Cloud-native AI pipelines
- High-efficiency inference workloads
- Research environments focused on TensorFlow ecosystems
One of the biggest strengths of TPUs is their ability to deliver exceptional performance-per-watt efficiency. For enterprises operating large AI clusters, this can translate into significant long-term operational savings.
However, TPUs are more specialized than GPUs and may involve ecosystem limitations depending on the frameworks and tools being used. Teams seeking maximum flexibility across multiple AI frameworks often prefer GPUs because of their broader compatibility.
AI Infrastructure Deployment Models: On-Premises, Cloud, and Hybrid
Deployment models determine how data is accessed, how quickly models can be trained and served, how costs scale over time, and how securely sensitive workloads are managed. Most organizations today rely on one of three approaches—on-premises, cloud, or hybrid—each offering distinct advantages depending on business priorities and technical requirements.
On-Premises AI Infrastructure: Maximum Control and Data Sovereignty
On-premise deployment refers to hosting AI infrastructure within an organization’s own data centers. This model provides complete control over hardware, networking, security policies, and data governance. It is often preferred by enterprises that operate in highly regulated industries such as banking, healthcare, defense, or government services, where data residency and compliance requirements are strict.
One of the strongest advantages of on-premise infrastructure is predictable performance. Since compute resources are dedicated and not shared with external tenants, organizations can fine-tune systems for consistent latency and throughput. It also allows deep customization of hardware stacks, including specialized GPUs, storage configurations, and network topologies.
However, this control comes with trade-offs. On-premise AI infrastructure requires significant upfront capital investment in hardware procurement, facility maintenance, and skilled personnel. Scaling is also slower, as expanding capacity involves purchasing and integrating new equipment. As AI workloads grow rapidly in size and complexity, this rigidity can become a limiting factor.
Cloud AI Infrastructure: Elasticity and Speed of Innovation
Cloud-based deployment has become the default choice for many AI teams due to its flexibility and rapid scalability. In this model, AI workloads run on infrastructure provided by cloud service providers, allowing organizations to provision compute resources on demand without managing physical hardware.
The biggest strength of cloud AI infrastructure is elasticity. Teams can scale GPU or CPU resources up or down based on workload intensity, making it especially useful for model training cycles, experimentation, and unpredictable traffic patterns. This pay-as-you-go model also reduces upfront costs, enabling startups and smaller organizations to access high-performance AI infrastructure without large capital expenditure.
Cloud environments also accelerate development cycles. Preconfigured AI services, managed machine learning platforms, and integrated data tools allow teams to move from experimentation to deployment quickly. This reduces operational overhead and enables faster iteration on models.
Despite these advantages, cloud deployments can introduce challenges such as long-term cost unpredictability at scale, potential vendor lock-in, and concerns around data privacy. Organizations handling sensitive or highly regulated data must carefully evaluate compliance capabilities and data residency options offered by cloud providers.
Hybrid AI Infrastructure: Balancing Flexibility and Control
Hybrid deployment combines the strengths of both on-premise and cloud models, allowing organizations to distribute workloads across environments based on their specific requirements. This approach is becoming increasingly popular as AI systems grow more complex and business needs become more diverse.
In a hybrid setup, sensitive data and critical workloads can remain on-premise, while the cloud is used for high-scale training, experimentation, or burst compute demands. This allows organizations to maintain control over critical assets while still benefiting from the scalability and speed of cloud infrastructure.
Hybrid models also enable workload optimization. For example, real-time inference systems might run in a private data center to minimize latency, while large-scale model training happens in the cloud where GPU resources can be provisioned temporarily at scale. This separation improves both performance efficiency and cost management.
However, hybrid environments require careful orchestration. Data synchronization, networking complexity, and consistent security policies across environments can introduce operational overhead. Successful implementation typically depends on strong DevOps practices, unified monitoring systems, and well-defined data governance frameworks.
Choosing the Right Deployment Model
There is no universal deployment strategy for AI infrastructure. The right choice depends on a combination of factors including regulatory requirements, budget constraints, workload characteristics, and scalability expectations.
- Organizations prioritizing strict control, security, and compliance often lean toward on-premise systems.
- Teams focused on agility, experimentation, and rapid scaling tend to favor cloud-based infrastructure.
- Enterprises with mature AI operations and diverse workload demands increasingly adopt hybrid architectures to optimize across both worlds.
Generative AI Infrastructure: What’s Different About LLM Workloads
Generative AI has reshaped how infrastructure teams think about performance, scalability, and cost. Unlike traditional machine learning systems that often focus on structured predictions or classification tasks, large language models (LLMs) and multimodal generative systems introduce a fundamentally different workload profile. These differences significantly impact how infrastructure must be designed and operated.
Key Differences in Generative AI (LLM) Infrastructure
High Compute Intensity and Parallel Processing Requirements
- LLMs built on transformer architectures depend heavily on large-scale matrix multiplications for both training and inference.
- This increases reliance on memory bandwidth, fast GPU-to-GPU communication, and efficient parallel execution.
- Infrastructure must therefore be optimized with high-performance GPUs, distributed training frameworks, and low-latency interconnects between compute nodes.
Memory-Heavy Context Processing
- Generative models often handle long input sequences, which significantly increases memory consumption.
- Attention mechanisms scale inefficiently as sequence length grows, placing pressure on GPU memory capacity.
- To manage this, systems require large VRAM GPUs along with techniques like model sharding and tensor parallelism to distribute memory load effectively.
Highly Variable Inference Workloads
- Unlike traditional ML systems that process relatively uniform requests, LLM inference workloads vary widely in complexity and response size.
- A simple query may require minimal compute, while a complex prompt can trigger extensive token generation and higher resource usage.
- This unpredictability makes dynamic scaling, autoscaling policies, and intelligent load balancing essential for stable performance.
New Operational and Serving Requirements
- Generative AI introduces unique infrastructure needs such as prompt caching to reduce redundant computation and improve latency.
- Token-based processing models and billing structures require more granular tracking of compute usage.
- Real-time streaming responses also demand optimized observability systems and fine-tuned latency management.
AI Infrastructure Costs: How to Optimize
As AI systems scale, infrastructure costs can quickly become one of the largest operational expenses. This is especially true for GPU-intensive workloads such as deep learning training and generative AI inference. Without careful planning, organizations can find themselves spending heavily on compute resources that are underutilized or inefficiently allocated. Optimizing AI infrastructure costs requires a combination of architectural decisions, workload management strategies, and ongoing monitoring.
Key Strategies for Optimizing AI Infrastructure Costs
Right-Sizing Compute Resources
- Avoid overprovisioning high-cost resources such as GPUs and high-memory instances “just in case.”
- Profile workloads to align model requirements with the most suitable compute tier.
- Use CPUs or smaller GPU instances for lightweight inference tasks, reserving high-end accelerators for intensive training workloads.
Workload Scheduling and Batching
- Replace continuous or unstructured job execution with planned scheduling to improve efficiency.
- Group training and inference tasks to maximize GPU utilization and reduce idle time.
- Apply request batching in inference pipelines to lower per-request compute cost while maintaining performance.
Cloud Cost Optimization Techniques
- Implement auto-scaling policies that adjust compute capacity dynamically based on demand patterns.
- Use spot instances or preemptible resources for non-critical training jobs to reduce infrastructure costs.
- Carefully manage interruptions in such instances to avoid disruptions in long-running workloads.
Model Optimization for Efficiency
- Apply techniques like quantization, pruning, and distillation to reduce model size and computational overhead.
- Smaller, optimized models require less GPU power, lowering both training and inference costs.
- Maintain a balance between efficiency gains and acceptable model accuracy.
Data Pipeline Optimization
- Eliminate inefficiencies such as redundant data storage, slow loading processes, and unnecessary data duplication.
- Improve data engineering workflows so that compute resources spend more time processing and less time waiting for input data.
- Optimize storage architecture to reduce both latency and cost overhead.
Observability and Cost Monitoring
- Track resource usage across training, inference, and experimentation environments in real time.
- Monitor metrics such as GPU utilization, memory consumption, and request throughput.
- Use insights from monitoring systems to identify inefficiencies, bottlenecks, and opportunities for cost reduction.
Ultimately, optimizing AI infrastructure costs is not about reducing capability—it is about improving efficiency. The most effective systems are those that balance performance and cost by aligning infrastructure decisions closely with workload behavior and business priorities.
Challenges in Scaling AI Infrastructure
AI infrastructure faces multiple hurdles as businesses attempt to scale AI solutions efficiently. Some key challenges include:
- Computational Power Constraints: AI workloads demand high-performance hardware, often requiring specialized GPUs and TPUs.
- Infrastructure Costs: Expanding AI infrastructure involves significant investment in cloud computing, storage, and networking.
- Talent Shortage: A lack of experienced AI engineers and data scientists remains a major barrier for enterprises.
- Leadership Support: AI adoption requires strategic alignment and executive buy-in to drive innovation.
The image below visually represents these challenges, offering insights into how organizations navigate AI infrastructure scalability. (Source: ClearML Research)

Comparison Table: AI Infrastructure vs. Traditional IT Infrastructure
Feature |
AI Infrastructure |
Traditional IT Infrastructure |
| Computational Power | GPUs, TPUs, AI accelerators | CPUs |
| Data Processing | Real-time streaming, parallel processing | Batch processing, sequential execution |
| Scalability | Elastic cloud computing, distributed systems | Fixed resources, on-premises servers |
| Networking | Low-latency, high-bandwidth (InfiniBand, RDMA) | Standard Ethernet, moderate bandwidth /td> |
| Storage | Distributed, scalable storage (Data lakes, object storage) | Centralized databases, structured storage |
| Security & Compliance | AI-specific governance, ethical AI frameworks | Standard IT security protocols |
| Energy Efficiency | Optimized for AI workloads, high power consumption | General-purpose computing, lower power needs |
MLOps: The Operating Model for AI Infrastructure
MLOps, short for Machine Learning Operations, is the discipline that connects machine learning development with production-grade infrastructure and operations. As AI systems move from experimental notebooks to mission-critical applications, MLOps becomes the operating backbone that ensures models are not only built effectively but also deployed, monitored, and maintained reliably at scale.
At its core, MLOps bring structure to the full lifecycle of an AI system. This includes data preparation, model training, validation, deployment, monitoring, and continuous improvement. Without this operating model, AI infrastructure tends to become fragmented models that live in silos; deployments are inconsistent, and performance degradation often goes unnoticed until it impacts users.
Standardizing the AI Lifecycle
One of the primary goals of MLOps is to standardize how machine learning workflows move through different stages. In traditional setups, data scientists may experiment in isolation, while engineering teams handle deployment separately. This separation often leads to inconsistencies between training and production environments.
MLOps addresses this by introducing repeatable pipelines. These pipelines ensure that data preprocessing, feature engineering, model training, and evaluation follow consistent processes. By automating these steps, organizations reduce human error and ensure that models behave predictably when deployed.
Continuous Integration and Continuous Delivery for Models
In modern AI infrastructure, models are not static artifacts. They evolve as data changes, user behavior shifts, and business requirements grow. MLOps extends the principles of CI/CD (Continuous Integration and Continuous Delivery) to machine learning systems.
Continuous integration ensures that new code, data updates, or model improvements are automatically tested before being merged into production workflows. Continuous delivery enables models to be deployed rapidly and safely, often through automated pipelines that reduce manual intervention.
Monitoring and Model Performance Management
Unlike traditional software systems, machine learning models can degrade over time even if the underlying code does not change. This phenomenon, often referred to as model drift, occurs when real-world data diverges from the data used during training.
MLOps introduces continuous monitoring as a core infrastructure capability. This includes tracking prediction accuracy, latency, data distribution shifts, and system performance metrics. When anomalies are detected, teams can retrain or adjust models before performance issues impact end users.
Automation and Infrastructure Scalability
Automation is another key pillar of MLOps. By automating repetitive tasks such as model retraining, testing, deployment, and rollback, organizations can scale AI systems more efficiently. This reduces operational overhead and allows teams to focus on improving models rather than managing infrastructure manually.
From an infrastructure perspective, MLOps integrates tightly with cloud and distributed systems. It enables dynamic resource allocation for training jobs, automated scaling for inference services, and seamless integration with data pipelines. This ensures that infrastructure adapts to workload demands rather than remaining static.
Governance, Reproducibility, and Collaboration
As AI systems become more complex, governance becomes critical. MLOps introduces version control for data, models, and experiments, ensuring that every change is traceable and reproducible. This is especially important in regulated industries where auditability is required.
It also improves collaboration between data scientists, ML engineers, and DevOps teams by providing shared tools and workflows. Instead of working in isolated environments, teams operate within a unified system where changes are transparent and reproducible.
MLOps as the Foundation of Scalable AI Infrastructure
Ultimately, MLOps transforms AI infrastructure from a collection of disconnected tools into a cohesive operational system. It ensures that models are not just built, but continuously improved, reliably deployed, and actively monitored throughout their lifecycle.
As organizations scale their AI initiatives, MLOps becomes less of an optional enhancement and more of a foundational requirement.
Benefits of AI Infrastructure
AI infrastructure is transforming industries by enhancing efficiency, scalability, and decision-making. Businesses investing in AI infrastructure experience higher productivity, cost savings, and competitive advantages.

1. Increased Computational Efficiency
AI models require high-performance computing (HPC) to process vast datasets. With AI workloads consuming 10x more computing power than traditional IT applications, enterprises are shifting to GPUs, TPUs, and AI accelerators for faster processing.
2. Cost Reduction & Operational Efficiency
AI-driven automation reduces manual labor costs and streamlines operations. According to Grant Thornton Research, AI-powered automation can cut operational expenses by 30-50%, improving overall efficiency.
3. Enhanced Scalability
With 90% of enterprises deploying AI-specific infrastructure, businesses can scale AI applications seamlessly (AI Infrastructure Alliance). Cloud-based AI solutions allow organizations to expand computing power on demand, eliminating infrastructure bottlenecks.
4. Improved Decision-Making
AI infrastructure enables real-time analytics, helping businesses make data-driven decisions. Companies using AI-powered analytics report a 25% increase in decision-making speed, leading to better strategic outcomes.
5. Faster Innovation
AI infrastructure fosters innovation by enabling advanced AI models for predictive analytics, automation, and personalization. 78% of organizations now use AI, with leading industries such as finance (61%), tech (85%), and retail (68%) leveraging AI for competitive growth. (AI Infrastructure Alliance)
Implementation Strategies for AI Infrastructure
To successfully deploy AI infrastructure, businesses must follow structured implementation strategies that ensure scalability, security, and efficiency. AI infrastructure is not a one-size-fits-all solution; it must be tailored to an organization’s unique operational needs, available resources, and long-term AI objectives.
Companies must invest in the right computing power, optimized data pipelines, and security frameworks to fully leverage AI capabilities.
1. Assess AI Readiness
Organizations must evaluate their current IT ecosystem, available data assets, and AI maturity level before implementing infrastructure upgrades. This ensures businesses identify technology gaps and resource limitations, allowing them to make informed decisions.
2. Invest in AI Talent
Deploying AI infrastructure requires skilled professionals in data science, cloud architecture, and machine learning. Companies should focus on training existing employees, partnering with AI research institutes, and hiring specialized AI engineers to ensure smooth execution.
3. Choose the Right AI Stack
Selecting the right AI tools, frameworks, and computing resources is crucial for achieving optimal model performance. Businesses must assess their hardware needs (GPUs, TPUs), cloud storage capabilities, and model development platforms to align AI infrastructure with their goals.
4. Optimize Data Management
AI models rely on structured, clean, and high-quality data for accurate predictions. Organizations should implement automated data pipelines, streamline data governance policies, and ensure data integrity before feeding AI algorithms.
5. Prioritize Security & Compliance
Since AI handles sensitive business data, organizations must implement robust cybersecurity measures and follow ethical AI regulations. Encryption, access controls, and privacy compliance should be key priorities in AI infrastructure planning.
6. Monitor AI Performance & Continuous Improvement
Deploying AI infrastructure is not a one-time task—it requires constant performance tracking, model refinement, and proactive troubleshooting. Using MLOps frameworks, businesses can identify efficiency bottlenecks and ensure continuous AI optimization.
Best Practices for Successful AI Infrastructure Deployment
To ensure AI infrastructure operates effectively, businesses should adhere to the following best practices:
1. Design a Scalable Architecture
AI workloads will evolve over time, demanding elastic computing power and flexible infrastructure scaling. Organizations should choose cloud-native solutions that provide on-demand scalability and resource allocation flexibility.
2. Standardize AI Governance & Ethical AI Policies
AI systems must be transparent, compliant, and ethically aligned with business goals. Companies should develop AI governance frameworks that outline data usage policies, bias mitigation strategies, and ethical decision-making standards.
3. Implement Cost-Efficient AI Infrastructure
AI infrastructure can be resource-intensive, making cost optimization essential. Businesses should evaluate hybrid cloud solutions, GPU/TPU cost efficiencies, and open-source AI tools to reduce overall expenditure.
4. Foster Cross-Team Collaboration
AI infrastructure deployment requires collaboration between IT, data science, and business strategy teams. Organizations should encourage knowledge sharing, interdepartmental training, and AI adoption workshops to align goals.
5. Build Resilient AI Models
Ensuring model reliability is key to successful AI applications. Businesses should implement fault-tolerant AI infrastructure, leverage edge computing for real-time analysis, and integrate disaster recovery plans.
Give Wings to Your AI Dreams with the Right AI Infrastructure
From compute resources to data pipelines, secure deployments, and compliance, AI infrastructure forms the invisible engine driving today’s most intelligent enterprises. But as powerful as AI can be, its success depends entirely on the strength of the infrastructure behind it.
And that’s where most organizations hit a wall—costly configurations, slow deployment, talent gaps, and fragmented tools to stall progress.
That’s where Everforth Quinnox AI (EQAI) Studio comes in—your launchpad for AI success.
With over 250+ AI and data experts, 70+ real-world use cases, and 50+ pre-built accelerators, EQAI Studio helps organizations leap over infrastructure hurdles. Whether you’re testing AI at a small scale or deploying enterprise-wide initiatives, its pre-configured, scalable environments eliminate the heavy lifting—so your teams can focus on building value, not just systems.
Because the future of AI isn’t just about algorithms—it’s about empowering people with the right infrastructure to create, innovate, and lead.
Get in touch with EQAI Studio today and turn your AI ambitions into reality!
FAQs on AI Infrastructure
AI infrastructure refers to the hardware, software, data systems, and networking tools required to support AI applications. It enables efficient data processing, model training, and real-time predictions at scale.
In enterprises, AI infrastructure powers everything from data collection and storage to model development, deployment, and monitoring. It ensures AI systems run smoothly, securely, and with high performance to support business goals.
Core components include high-performance computing (GPUs/TPUs), scalable data storage (data lakes/warehouses), development tools (ML frameworks), model deployment platforms, and governance tools for security and compliance.
It boosts productivity, speeds up innovation, improves decision-making, lowers operational costs, and provides scalable AI capabilities to meet growing business demands.
AI infrastructure is designed for high-speed data processing and complex model training, using tools like GPUs, real-time data streams, and AI-specific governance. Traditional IT focuses more on general computing with slower, sequential processing.
AI infrastructure is the foundation that supports artificial intelligence applications, enabling them to process vast amounts of data efficiently. It integrates hardware, software, networking, and data management solutions to optimize AI workloads, ensuring scalability, speed, and compliance. A well-structured AI infrastructure ensures seamless data flow for AI models, efficient computing power to process complex algorithms, scalable solutions for handling increasing AI demands, and secure and compliant frameworks for AI governance.
Best practices for deploying AI infrastructure in a hybrid cloud environment include building a scalable and modular architecture, integrating high-performance computing resources (such as GPUs) with cloud-native services, maintaining consistent data governance across on-premise and cloud environments, and designing for workload portability so AI models can run wherever compute is most cost-effective or compliant.
A key design goal of AI network infrastructure is to ensure high-throughput, low-latency data movement that keeps pace with AI model training and inference demands. The network must support fast, reliable data transfer between storage, compute, and model-serving layers to eliminate bottlenecks that would otherwise degrade AI performance.
The best infrastructure for deploying AI models depends on the scale and sensitivity of the workload. Generally, a hybrid approach — combining on-premises GPU clusters for latency-sensitive or data-sensitive workloads with cloud-based scalable compute for burst training — provides the flexibility, performance, and cost efficiency most enterprises need.
Managing AI infrastructure elasticity involves designing systems that can automatically scale compute and storage resources in response to fluctuating AI workloads, using auto-scaling policies, containerized deployments (such as Kubernetes), and cost-aware scheduling to ensure resources are provisioned on demand and released when no longer needed.
A GPU is a general-purpose parallel processor widely used for AI training and inference across many frameworks. A TPU is a custom-built accelerator optimized specifically for tensor operations in deep learning, especially large-scale models. In simple terms, GPUs offer flexibility and broad compatibility, while TPUs focus on higher efficiency for large neural network workloads.
MLOps is the practice of managing the end-to-end machine learning lifecycle—building, deploying, monitoring, and maintaining models in production. It matters because it ensures AI systems are reliable, scalable, and continuously improving instead of breaking or degrading after deployment.
Generative AI and LLMs typically require high-performance GPUs with large memory, distributed training setups, fast interconnect networks, and scalable storage. In most cases, a cloud or hybrid setup is used to handle heavy training workloads and variable inference demands efficiently.