Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
|
Modern digital systems are more complex, distributed, and interdependent than ever before. From cloud-native architectures and container orchestration to third-party integrations and global traffic routing, the operational landscape has evolved rapidly, outpacing traditional approaches to reliability and system testing. While this architectural shift has enabled rapid scaling and innovation, it’s also introduced new challenges that are often difficult to predict and even harder to control.
For engineering teams, these challenges manifest in ways that directly affect the business, leading to unexpected downtime, degraded performance, and outages that ripple across environments. As per Gartner, unplanned downtime can cost companies an average of $5,600 per minute, affecting customer trust, revenue, and operational continuity. That’s not all, according to a IDC survey, for Fortune 1,000 companies, downtime could cost between $1 million and $2.5 billion per hour while large enterprises can spend as much as $60 million or more.
So, how do you build systems that gracefully handle unplanned downtime, scale under pressure, and maintain reliability amidst unpredictability?
This is where Chaos Engineering steps in not as a theoretical concept, but as a practical discipline, that allows teams to proactively test their assumptions, identify vulnerabilities, and strengthen system behavior under duress.
In this blog, we’ll explore Chaos Engineering in depth, covering its core principles, its business and technical benefits, and the practices that make it an effective strategy for building modern, reliable software systems.
What is Chaos Engineering?
Chaos Engineering is a structured methodology for identifying vulnerabilities in complex systems by intentionally injecting failure into those systems and observing how they respond. Instead of relying solely on monitoring tools, logs, and post-mortems, chaos engineering goes a step further by creating real-world failure scenarios in controlled environments.
Think of it as a fire drill for your software systems. You don’t wait for a fire to check your exit routes—you simulate one to ensure the alarms sound and the doors open. In the same way, chaos engineering helps teams answer questions like:
- What happens if a critical microservice goes down?
- Can our system handle a sudden spike in traffic?
- What if a network partition occurs between two data centres?
Register for Webinar Now: The ABCD of Chaos Engineering: Breaking Bad with Qinfinite
The Evolution and History of Chaos Engineering
The concept originated during Netflix’s transition to cloud-native infrastructure in the early 2010s. As they moved to Amazon Web Services, the engineering team faced a fundamental problem where traditional testing practices proved insufficient for the unpredictable nature of large-scale, distributed systems.
To address this, they created Chaos Monkey, a tool that randomly terminated virtual machine instances. The idea was straightforward—if a service couldn’t tolerate the loss of a node, it wasn’t production-ready. Over time, this practice expanded into a suite of tools called the Simian Army, capable of simulating more complex failure scenarios such as regional outages and network latency.
The success of this initiative—and the stability it brought to Netflix’s platform—spurred broader industry adoption. Over the past decade, organizations like Google, LinkedIn, Amazon, and Shopify have embraced chaos engineering as a core practice, incorporating it into their Site Reliability Engineering (SRE) and incident response frameworks.
Top 5 Chaos Engineering Principles
Chaos Engineering is often misunderstood as a practice that focuses on breaking systems randomly, instead of looking at it as a rigorous, scientific discipline grounded in a clear set of principles. These principles differentiate Chaos Engineering from traditional failure testing or ad hoc troubleshooting. They provide a structured methodology for uncovering systemic weaknesses and improving system resilience through intentional, controlled experiments.
Let’s examine each chaos engineering principle in depth:
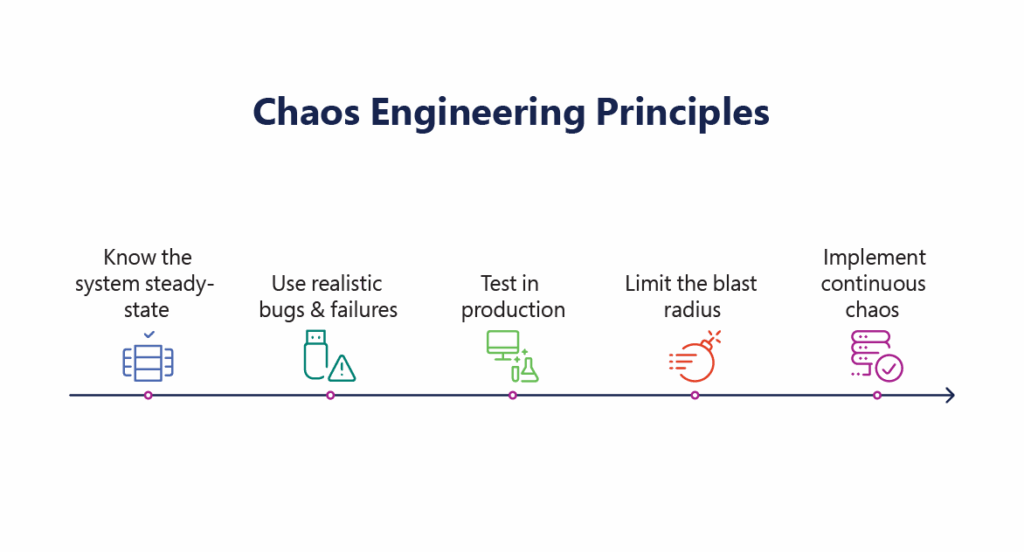
1. Build a Hypothesis around Steady-State Behavior
Before introducing any failure, teams must formulate a hypothesis: “If condition X occurs, then the system should continue to exhibit behavior Y.” For example, if a database node fails, the application should still serve requests within acceptable latency boundaries due to redundancy mechanisms. This hypothesis serves as a reference point, allowing engineers to detect when the system deviates from its expected performance.
2. Varying Real-World Events
Software systems don’t fail in isolation. Real-world failures manifest in a wide variety of forms—hardware crashes, network congestion, memory leaks, cascading service dependencies, cloud provider outages, and more. To prepare systems for such realities, Chaos Engineering encourages the deliberate and strategic injection of these failure modes into a system.
This principle involves replicating plausible scenarios rather than synthetic or contrived conditions. For example, engineers may simulate:
- Termination of a compute instance or container,
- Network latency between microservices,
- Throttling of third-party APIs,
- Disk space exhaustion on key services,
- Packet loss or partial outages in specific availability zones.
By closely mimicking production-like failure conditions, teams can observe how the system behaves under realistic stress and validates whether its fault-tolerance mechanisms respond effectively.
3. Run Experiments in Production or Production-Like Environments
A common pitfall in software reliability is assuming that what works in a staging environment will necessarily hold up in production. In reality, production systems exhibit unique behaviors due to scale, unpredictable usage patterns, third-party integrations, and deployment-specific configurations that are difficult or impossible to replicate in test environments. Hence, running chaos experiments in production or in environments that closely resemble production is essential.
4. Automate Experiments and Run Continuously
Reliability is not a one-time achievement; it is a moving target. Systems evolve—new services are deployed, dependencies shift, traffic patterns change, and teams iterate rapidly. A resilient system today may become fragile tomorrow. That is why chaos experiments must be repeatable, automated, and executed continuously as part of the software delivery lifecycle.
Automation ensures that fault-injection scenarios are not left to occasional manual execution but are instead embedded in CI/CD pipelines, release gates, and monitoring workflows. Platforms like Qinfinite enable teams to schedule and execute these experiments with precision and consistency.
5. Minimize Blast Radius
Perhaps the most important task, particularly for teams early in their Chaos Engineering journey, is to limit the impact of experiments. The goal is not to induce outages, but to gain insight safely and responsibly.
- Limiting the blast radius can be achieved in several ways:
- Targeting non-critical services,
- Running experiments during low-traffic windows,
- Scoping experiments to a single instance or a small subset of traffic,
- Implementing automatic rollback mechanisms,
- Monitoring closely with real-time observability tools.
As teams mature in their practices and build institutional confidence, the scope of experiments can be expanded gradually. However, risk containment remains a central discipline even in advanced chaos programs, ensuring that the pursuit of reliability never compromises business continuity.
Key Benefits of Practicing Chaos Engineering
Chaos Engineering, while rooted in the practice of intentionally inducing faults, brings a wealth of tangible and intangible benefits that span technical, operational, and organizational realms. When done correctly, it transforms how teams perceive system reliability, offering substantial improvements that extend beyond the immediate scope of fault tolerance.
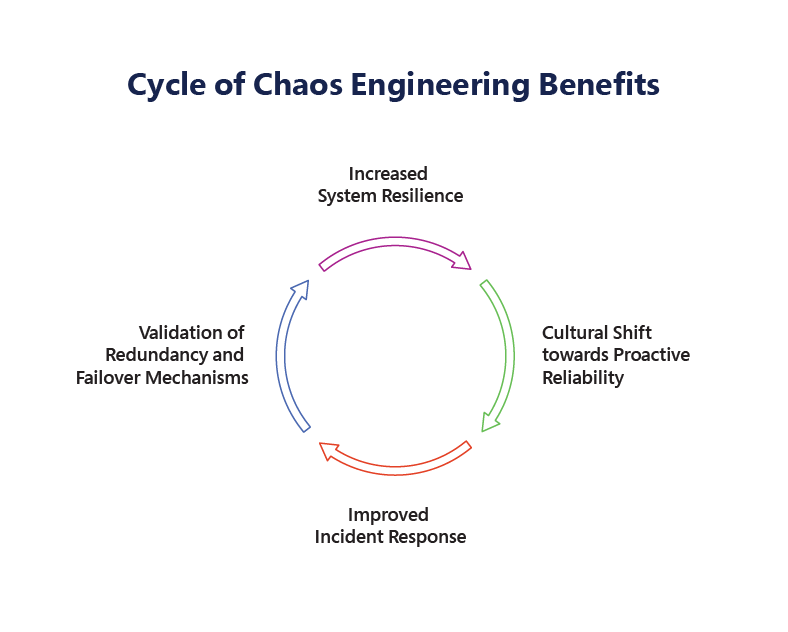
Below, let us explore the multifaceted advantages of practicing Chaos Engineering in detail:
1. Increased System Resilience
One of the most profound outcomes of Chaos Engineering is increased system resilience. Resilience, in the context of software and infrastructure, refers to a system’s ability to recover from disruptions and continue functioning at an optimal level despite unforeseen failures. By continuously testing a system’s boundaries, Chaos Engineering uncovers weak links that might otherwise remain hidden in normal operations.
For example, by simulating server crashes, network partitioning, or resource exhaustion, engineering teams can observe how the system reacts and identifies any failure points that compromise its overall stability. Once these vulnerabilities are detected, teams can address them proactively, whether through improving fault tolerance mechanisms, scaling infrastructure, or implementing more robust redundancy strategies.
2. Improved Incident Response
The ability to respond swiftly and efficiently to incidents is a critical aspect of operational excellence. Chaos Engineering plays a key role in this by enabling teams to understand the myriads of potential failure modes that could affect their systems.
By intentionally introducing disruptions in a controlled environment, teams can gain valuable insights into how their systems break under pressure. These controlled failures serve as practice runs for real incidents, allowing engineering teams to identify potential bottlenecks, inefficiencies, or blind spots in their response strategies. By having practiced different scenarios in advance, they become more adept at diagnosing root causes, implementing recovery protocols, and ultimately reducing Mean Time to Recovery (MTTR).
3. Cultural Shift towards Proactive Reliability
Perhaps one of the most profound and often overlooked benefits of Chaos Engineering is the cultural shift it fosters within an organization. Traditional software development models often operate on a reactive basis: waiting for incidents or failures to occur and then scrambling to patch or fix them. Chaos Engineering flips this script by encouraging proactive reliability.
Through the practice of chaos experiments, organizations are not merely responding to failures—they are actively seeking them out, understanding them, and learning from them. This fosters a mindset of continuous improvement and experimentation, where teams view failures not as setbacks but as opportunities to grow, evolve, and enhance their systems.
Operational Intelligence
Many enterprises struggle with fragmented visibility across supply chains, finance, production lines, and support operations. By integrating data across ERP systems, third-party vendors, customer orders, and sensor logs, Knowledge Graphs build a unified operational model. This allows businesses to identify process inefficiencies, pinpoint root causes of delays, and uncover dependencies that impact timelines or cost .
4. Validation of Redundancy and Failover Mechanisms
Redundancy and failover mechanisms are core components of any resilient system. However, merely implementing these mechanisms is not enough to ensure they will work when needed most. This is where Chaos Engineering proves invaluable. Through chaos experiments, teams can validate the effectiveness of their redundancy and failover strategies in real-world conditions.
For instance, by simulating the failure of a database server, engineers can test whether traffic is properly rerouted to a backup system without degrading performance. Similarly, introducing network latency allows teams to observe how well the system’s circuit breakers function to prevent cascading failures, or how load balancers manage traffic distribution during peak loads or partial outages.
How to Implement Chaos Engineering Effectively: 5 Best Practices to Follow
Implementing Chaos Engineering is more than just running a few stress tests or introducing failure into a system. To implement it effectively, you need to approach it systematically, ensuring that it becomes a deeply integrated part of your organization’s operational philosophy. This requires aligning not only the technical aspects, such as tools and frameworks, but also fostering a culture of collaboration, learning, and proactive reliability.
Here are the five best chaos engineering practices that you can follow to ensure that the process of inducing failure is controlled, valuable, and ultimately strengthens your system’s overall resilience.
1. Start Small: Begin with Low-Risk Experiments in Non-Critical Systems
When first integrating Chaos Engineering into your organization’s workflow, it is crucial to start small. Avoid the temptation to dive straight into high-stakes experiments, such as network failures in critical user-facing services. Instead, begin with low-risk, controlled experiments within non-critical systems.
For example, you could simulate a failure within an internal service or a background job that does not directly affect your end-users. These smaller experiments allow teams to build familiarity with the tools and processes involved in Chaos Engineering without the risk of significant disruptions. They also offer a safe environment to observe how the system reacts to failures and how recovery processes work in real-world scenarios.
Starting small serves a few key purposes:
- It minimizes potential damage while you’re still learning the nuances of your systems.
- It provides early wins in understanding the impact of different failure modes.
- It builds confidence among team members and stakeholders that Chaos Engineering can be a controlled and non-destructive process.
As your team gains experience and the system matures, you can incrementally increase the scope of the experiments.

2. Collaborate Across Teams: Engage Developers, Operations, and SREs in Planning and Execution
Chaos Engineering is not just the responsibility of a single team. It is inherently a cross-functional practice that benefits from input and collaboration from multiple departments. Successful implementation requires the active involvement of developers, operations teams, and Site Reliability Engineers (SREs) at every stage of the process.
- Developers: They have a deep technical understanding of application behavior, codebase, and potential failure points. Their knowledge is crucial for designing relevant chaos experiments and understanding how to address bugs or vulnerabilities that arise during experimentation.
- Operations teams: They manage the infrastructure and have a solid understanding of system-level failures (e.g., server crashes, resource exhaustion). They also ensure that the system’s scaling and redundancy mechanisms work smoothly under stress.
- SREs: Site Reliability Engineers bridge the gap between development and operations, focusing on building resilient systems, monitoring, and automating processes. They are often key to integrating Chaos Engineering practices into the CI/CD pipeline and ensuring that the experiments don’t jeopardize system availability.
Collaborating across these disciplines not only ensures that chaos experiments are realistic and aligned with the system’s architecture but also fosters a shared understanding of system reliability.
3. Instrument Observability Tools: Use Logging, Tracing, and Metrics to Detect Deviations in Steady-State
To ensure that chaos experiments provide actionable insights, it is essential to have comprehensive observability in place. Without proper logging, tracing, and metrics, you will not be able to detect subtle deviations from the system’s steady-state behavior when an experiment is running.
The first step is to define what constitutes “steady-state” behavior. This could involve measuring metrics such as:
- Latency: How long does it take for the system to respond to requests under normal conditions?
- Throughput: How many transactions or requests is the system processing per unit of time?
- Error rate: What percentage of requests are failing or producing errors?
- Resource utilization: What is the system’s CPU, memory, and network usage like under normal operations?
Once these baselines are established, you can design your experiments to deviate from steady-state conditions intentionally. During an experiment, real-time observability helps teams track how the system behaves as it encounters failures. By integrating logging, tracing, and monitoring tools into your Chaos Engineering efforts, you can identify not only when something goes wrong, but also why it went wrong.
4. Leverage Platforms like Qinfinite to Accelerate and Simplify Chaos Engineering Implementation
While implementing Chaos Engineering from scratch is possible, there are many powerful platforms and tools available to help accelerate the process and make it more efficient. These tools provide pre-built frameworks that allow teams to run chaos experiments without needing to build everything from the ground up.
By using platforms like Qinfinite, teams can reduce the complexity of chaos engineering experiments while still maintaining flexibility and control with pre-built chaos scenarios, automated fault injection, and seamless integration with existing ITSM workflows. By automating key aspects and providing continuous feedback loops, Qinfinite makes Chaos Engineering more efficient, reducing the manual effort and enabling faster, more accurate resilience testing across systems.
5. Establish Safety Nets: Include Abort Mechanisms, Scope Limitations, and Real-Time Monitoring During Experiments
Chaos Engineering, by its very nature, involves inducing failure; however, this should always be done with a safety-first mindset. You never want to risk a full system outage or a catastrophic event due to an unanticipated result of a chaos experiment.
To mitigate risk, abort mechanisms and scope limitations for every experiment must be established. For instance, limit the experiment to a specific service or region, and define clear rules for what constitutes a failure that will trigger an automatic abort. If an experiment begins to affect a larger part of the system or exceeds predefined thresholds, an automated mechanism should immediately halt the experiment to avoid widespread disruption.
Common Misconceptions and Challenges in Chaos Engineering
As Chaos Engineering gains traction in various industries, several misconceptions and challenges persist, often hindering its successful implementation. Let’s address these misconceptions and explore the challenges that come with incorporating Chaos Engineering into an organization.
Misconceptions:
1. Chaos Engineering is about breaking things
One of the most pervasive myths is that Chaos Engineering is a reckless pursuit designed to deliberately break things for the sake of disruption. While it’s true that Chaos Engineering involves inducing failures, the ultimate goal is far more structured and scientific.
In reality, Chaos Engineering is about learning and gaining a deep understanding of how systems behave when exposed to failures and stresses. By observing the system’s response to controlled disruptions, teams can pinpoint vulnerabilities, strengthen recovery mechanisms, and build confidence in their ability to maintain service continuity even during adverse events.
2. It’s only for large-scale systems like Netflix or Amazon
Another misconception is that Chaos Engineering is only relevant for large-scale organizations with complex systems, like Netflix, Amazon, or Google. While these companies pioneered the practice at scale, the principles of Chaos Engineering are just as beneficial for smaller organizations, and the practices can be scaled down for smaller systems.
Chaos Engineering helps organizations of all sizes to identify failure points in their services and validate their resiliency strategies. For instance, an e-commerce startup could simulate a payment gateway failure to test fallback mechanisms, while a small SaaS provider might simulate a server crash to ensure their auto-scaling and recovery mechanisms are effective.
3. Chaos should be random
Chaos Engineering is not about random destruction or testing systems with arbitrary failures. A common misconception is that chaos experiments are unpredictable, uncontrolled, and designed simply to introduce mayhem. In fact, each chaos experiment is hypothesis-driven and rooted in scientific inquiry.
Before running an experiment, teams must define a hypothesis, such as, “If we introduce network latency between the app and database, will the system recover within the specified time window?” This approach allows teams to observe specific outcomes and measure the system’s ability to tolerate and recover from particular failure modes.
Challenges:
While the benefits of Chaos Engineering are clear, there are several challenges organizations face when adopting this practice. Understanding these challenges and having strategies to address them is key to successful implementation.
1. Organizational Resistance
One of the most significant challenges is organizational resistance. Chaos Engineering involves deliberately introducing failure into the system, which often worries teams about concerns around how running chaos experiments may disrupt customer experience, leading to downtime, or damage customer trust.
To overcome this, communication is crucial. Leadership must help the organization understand the long-term benefits of resilience and system reliability. As teams see the benefits of Chaos Engineering in improving system reliability, the practice will gradually gain traction.
2. Inadequate Observability
Chaos Engineering heavily relies on observing system behavior during experiments. If systems lack proper observability tools—such as logging, monitoring, tracing, and alerting—it can be difficult to detect and analyze the effects of induced failures. Without these insights, the practice of Chaos Engineering is rendered ineffective.
3. Fear of Disrupting Customer Experience
There is an understandable concern that introducing failure into production environments could disrupt customer experience. Companies worry that chaos experiments will cause service outages, leading to negative user experiences, loss of revenue, or brand damage.
Use Cases of Chaos Engineering
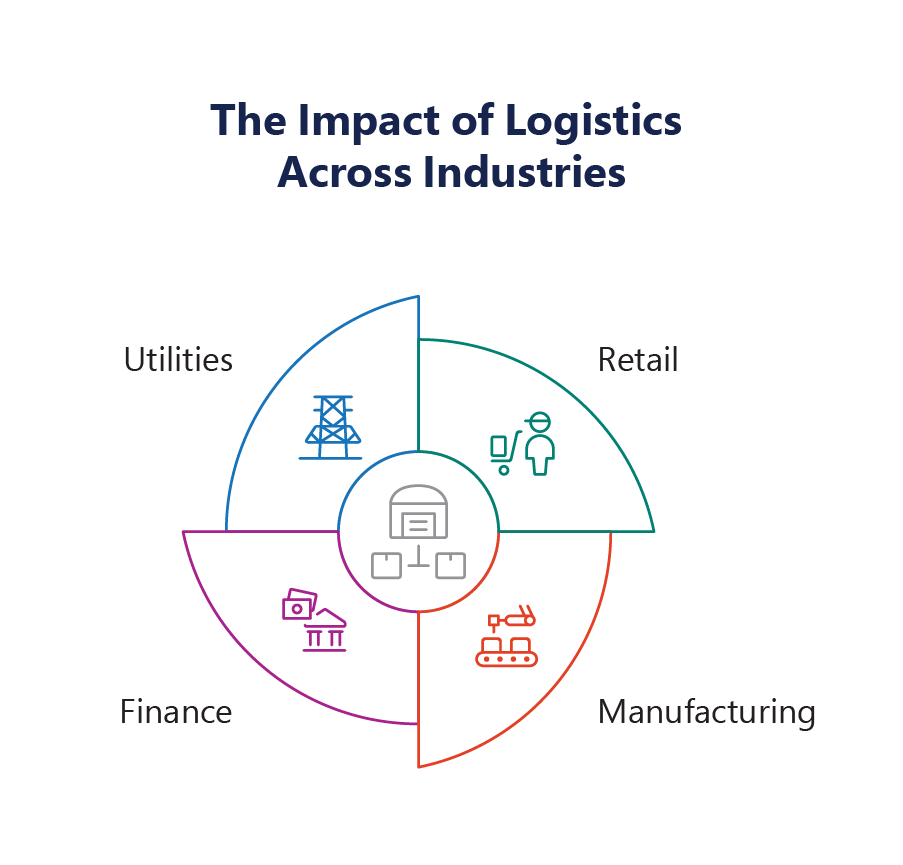
Chaos Engineering has a wide range of use cases across various industries. By testing systems in different environments and contexts, organizations can validate their disaster recovery strategies, ensure regulatory compliance, and guarantee system performance under stress.
Logistics:
In the logistics industry, ensuring timely delivery is critical. Chaos engineering can simulate failures in routing, communication between vehicles, or supply chain systems to identify weaknesses in delivery management software. By injecting chaos, teams can test how the system reacts to disruptions like truck breakdowns, delays, or incorrect route suggestions.
Manufacturing:
In the manufacturing industry, chaos experiments can target factory automation systems, such as sensors or control systems, to simulate failures like machine breakdowns or communication issues between machines.
By running chaos tests, manufacturers can improve the reliability of their automation systems and avoid unexpected downtime, which could halt production lines and impact product quality.
Retail:
Chaos engineering can simulate traffic spikes, such as those occurring during sales events or seasonal promotions, to test how the e-commerce platform handles increased load. Retailers can simulate slow database queries, crashes, or service disruptions to ensure that their websites and apps remain responsive even during high demand, preventing lost revenue and poor customer experience.
Finance
BFSI organizations can ensure the integrity and availability of critical systems, minimizing the risk of financial data corruption and improving customer confidence in their services. Chaos engineering can simulate failures in core banking systems, such as database crashes or disruptions in the payment processing pipeline, to test the robustness of financial applications.
Utility
In the utility sector, chaos engineering can be used to simulate failures in smart grid systems that manage electricity distribution. By introducing faults such as network latency, faulty sensors, or outages, utilities can test how their infrastructure adapts to disruptions and ensures continued service.
Types of Chaos Engineering Experiments
To effectively test system resilience, teams can conduct several types of chaos experiments:
1.Kill Specific Services
Test how the system behaves when a critical service is unexpectedly terminated. This experiment is useful for understanding the downstream impact and ensuring that failover mechanisms work correctly.
2. Network Latency Injection
Simulate slow or dropped network packets between services to test how the system manages delayed communication. This is particularly useful in microservices architectures where services depend on fast, reliable network communication.
3. Disk I/O Saturation
Simulate a scenario where storage resources are saturated or performing poorly. This helps test how applications perform under degraded storage performance and ensures that they can still function during resource exhaustion.
4. Region Failover Simulation
Test multi-region deployments by simulating an entire region failure. This experiment ensures that the system can continue functioning in the event of an availability zone or data center failure, with minimal impact on service availability.
Each experiment should follow a structured lifecycle:
- Define the hypothesis: What behavior do you expect?
- Introduce the fault: Simulate the failure.
- Observe system behavior: Track metrics, logs, and traces.
- Analyze results: Understand what worked, what didn’t, and how to improve the system.
Getting Started: Chaos Engineering Roadmap for Your Team
Successfully adopting Chaos Engineering involves a structured approach that minimizes risk while accelerating the process. The following roadmap will guide teams through the initial stages of adopting this practice.
1.Assess Readiness
Evaluate your system’s current resilience and your team’s readiness to embrace Chaos Engineering. Identify gaps in monitoring, tooling, and the organization’s culture around risk management.
2.Define Clear Objectives
Align chaos experiments with your business goals and reliability objectives. Whether improving uptime, validating failover strategies, or ensuring compliance, ensure that the experiments align with key operational metrics.
3.Choose the Right Tools & Platforms
Select tools and platforms based on your system architecture, cloud provider, and team expertise.
4.Start in Development or Staging
Run your initial experiments in development or staging environments to validate your tooling and experiment design without risking production systems.
5.Establish Governance
Define roles, responsibilities, and safety guidelines for running chaos experiments. This includes specifying who can run experiments, when they can run, and what safety mechanisms are in place.
6.Integrate into SDLC
Integrate chaos experiments into your CI/CD pipeline and incident management workflows. This ensures that reliability testing becomes a part of your everyday development cycle.
Wrapping Up the Chaos: Final Thought
The future is one where resilience is embedded into the very fabric of operations. As companies continue to scale and adopt dynamic infrastructures, Chaos Engineering will remain a key tool in building not just reliable systems, but a more resilient tomorrow.
What began as an experiment in fault tolerance has grown into a mature discipline that empowers organizations to build stronger, more resilient systems. Chaos Engineering is no longer just about breaking things on purpose—it’s about learning, improving, and preparing for the unknown.
The sooner you begin, the more prepared you will be for whatever comes next.
FAQs Related to Chaos Engineering
Chaos engineering is all about intentionally introducing controlled failures into a system to test how resilient it is. The goal is to simulate disruptions like network issues, server crashes, or sudden traffic spikes and observe how the system responds under stress. By doing this, we can uncover weaknesses that might not be obvious in normal conditions.
Why is it important? Well, in today’s world, systems are getting more complex, and no matter how robust they seem, they’re bound to fail at some point. Chaos engineering helps us build better and more reliable systems by addressing potential issues before they cause major disruptions.
Chaos engineering is guided by a few key principles:
Experiment in production: The best way to understand how your system behaves is by testing it in the real environment where it operates. That means experimenting in production systems—though always in a controlled manner, of course.
Start small: You don’t want to cause a huge disruption right away. Begin with smaller, low-risk experiments, like testing a single service failure, then gradually scale up as you build confidence.
Hypothesize: Before running an experiment, make a prediction about what you think will happen. Will your system degrade gracefully, or will it crash? This hypothesis guides your experiment and helps you analyze the outcome.
Monitor and learn: Chaos engineering is all about learning from failure. Once the experiment is done, analyze the results, understand what went wrong, and make improvements to the system’s design.
Chaos engineering can bring a lot of advantages to your team and your systems:
Improved system reliability: By continuously testing your system’s limits, you find weaknesses and fix them before they cause real issues.
Faster issue resolution: You get better at identifying and resolving problems more quickly since you’re always practicing under real-world conditions.
Better preparedness: With chaos experiments, you can simulate everything from hardware failures to network slowdowns, so your team is always prepared for any situation.
Increased confidence: The more you test your system’s resilience, the more confident you’ll be that it can handle unexpected disruptions when they occur in the real world.
Chaos engineering is deeply intertwined with both DevOps and Site Reliability Engineering (SRE) because all three focus on improving the reliability and performance of systems.
DevOps aims to streamline collaboration between development and operations teams. Chaos engineering aligns perfectly with this by providing developers and operators with real-world feedback on how their code behaves in production. It encourages continuous improvement and testing throughout the development lifecycle.
SRE is about ensuring the reliability of systems at scale. Chaos engineering is a great tool for SREs because it helps them simulate failures in a controlled way, allowing them to identify areas where reliability can be improved. It helps them define service level objectives (SLOs) and ensures that systems remain reliable under varying conditions.
In both DevOps and SRE, the idea is to shift left—by catching and addressing problems earlier in the development process—rather than waiting until they become major incidents.
There are several key practices that organizations typically follow when implementing chaos engineering:
Fault injection: This is where you deliberately cause failures, like dropping packets or turning off a service, to see how your system handles it.
Latency injection: Introduce network delays or simulate slow responses to test how the system reacts under performance bottlenecks.
Resource exhaustion: Simulate situations where your system runs out of resources, like CPU or memory, to see how it manages these resource constraints.
Simulating network partitions: This involves splitting communication between services to check how your system copes with a lack of connectivity or data loss.
Failure testing in microservices: Microservices are designed to be resilient, but chaos engineering can help test if they truly function well when individual services fail or are unavailable.
Here are a few practical examples of chaos engineering experiments you might run:
Simulating a server crash: You can simulate a server failure to see how the system responds, whether it reroutes traffic to healthy servers or if users experience downtime.
Network failure: Simulate a network outage between two services to check if your system can handle such disruptions. Does the service fail gracefully, or do you lose data or connectivity?
Database latency: Introduce delays to database queries to see how your application performs when its data retrieval times increase. Does it handle the lag, or does performance degrade?
Load testing during a traffic spike: Mimic an influx of users to see how your site or service handles an increased load. This can identify if you have enough scaling mechanisms in place to handle peak times.