Introduction
Data is the fuel that powers modern AI systems. Without vast amounts of relevant, diverse, accurate, and ethically sourced data, even the most advanced AI models struggle to perform reliably. Enterprises today face mounting obstacles in acquiring and managing such data. Privacy regulations are becoming stricter, data labeling is expensive, bias in datasets remains a major concern, and many industries simply do not have enough usable data to train robust AI systems.
This is where synthetically data generation is emerging as a transformative force.
Synthetic data – artificially generated information that mimics real-world data patterns – has evolved from a niche concept into a strategic enabler for AI development. Organizations are increasingly using synthetically generated datasets to accelerate innovation, improve model accuracy, reduce operational costs, and maintain compliance with evolving privacy standards.
More importantly, synthetic data is no longer limited to filling data gaps. It is becoming deeply integrated across the entire AI lifecycle – from data preparation and model training to evaluation, validation, deployment, and continuous improvement.
This blog explores how synthetic data is reshaping the future of AI development and why forward-looking enterprises are making it central to their AI strategies.
Why Data Is the Real Bottleneck in AI Innovation
But before exploring the role of synthetic data, it is important to understand why data itself has become the biggest enabler and often the biggest constraint in AI innovation.
No matter how advanced an AI model may be, its effectiveness ultimately depends on the quality of the data it is trained on. Organizations today are investing heavily in sophisticated algorithms, cloud infrastructure, and computing power, yet many AI initiatives still struggle to deliver meaningful outcomes because of one fundamental challenge: access to high-quality, reliable, and scalable data.
Building effective AI systems requires datasets that are not only large in volume, but also diverse, representative, accurate, and free from bias. Achieving this is far more difficult than it sounds.
Several factors contribute to this growing challenge:
- Sensitive customer and enterprise data cannot always be freely accessed or shared
- Real-world datasets are often incomplete, inconsistent, or heavily imbalanced
- Rare but critical events are difficult to capture in meaningful volumes
- Data labeling and annotation demand significant time, cost, and human effort
- Evolving regulatory and compliance requirements restrict how data can be collected and used
- Legacy systems frequently create fragmented data environments with poor interoperability
Consider the example of a fraud detection model in the banking sector. Fraudulent transactions typically represent only a very small percentage of total transactions, making it difficult for AI systems to learn enough fraud patterns effectively. Similarly, in healthcare, obtaining sufficient patient data for rare diseases is often nearly impossible, limiting the accuracy and reliability of diagnostic AI models.
These limitations create a significant bottleneck in AI development, slowing innovation, experimentation, and deployment.
This is precisely where synthetic data is emerging as a game-changing capability. By generating realistic, controlled, and scalable datasets that mirror real-world patterns, synthetic data enables organizations to overcome many of the constraints associated with traditional data collection.
Instead of spending months sourcing, cleaning, labeling, and governing real-world data, enterprises can rapidly create high-quality synthetic datasets tailored to specific AI objectives and generate large volumes of synthetic data that preserve statistical relevance while minimizing risk and operational complexity. The result is faster AI innovation with fewer limitations.
Reimagining Data Readiness: Smarter Collection and Preparation with Synthetic Data
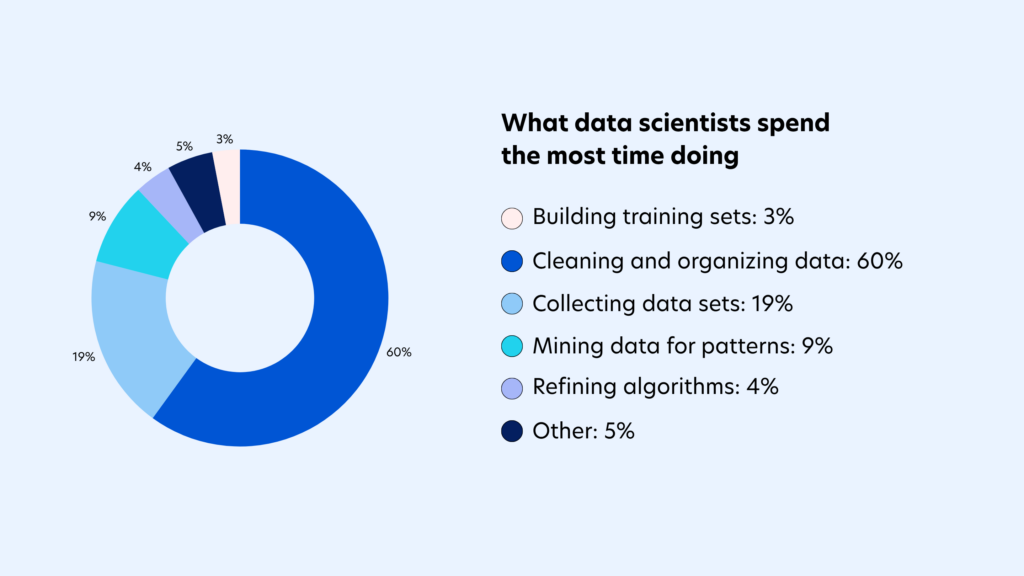
Data collection and preparation account for a substantial share of the AI development lifecycle. In many organizations, teams spend significantly more time sourcing, cleaning, organizing, and labeling data than they do actually building or training AI models. In fact, studies show that data scientists spend more than 60% of their time preparing data, making data preparation one of the biggest bottlenecks in accelerating AI innovation.
Synthetic data dramatically improves this process by:
1. Filling Data Gaps
Real-world datasets are rarely complete. Missing values, limited examples, and skewed distributions often reduce model effectiveness.
Synthetic data can augment existing datasets by generating additional records that reflect realistic patterns and relationships. This helps create balanced datasets capable of improving model performance.
For example:
- Retailers can simulate customer purchasing behaviors
- Manufacturers can generate machine failure scenarios
- Financial institutions can create synthetic fraud patterns
- Healthcare providers can simulate rare disease cases
2. Reducing Annotation Costs
Labeling large datasets manually is expensive and time-intensive. Synthetic data allows labels to be automatically generated alongside the data itself, significantly reducing annotation effort.
Computer vision applications particularly benefit from this approach. Autonomous vehicle systems, for instance, can generate thousands of labeled driving scenarios without requiring manual image tagging.
3. Improving Diversity and Representation
Bias in AI systems often originates from underrepresented data populations. Synthetic data can intentionally create balanced demographic representation, helping improve fairness and inclusivity.
This is especially useful in:
- Hiring algorithms
- Healthcare diagnostics
- Insurance underwriting
- Credit scoring systems
Synthetic data enables organizations to proactively address data imbalance before models enter production.
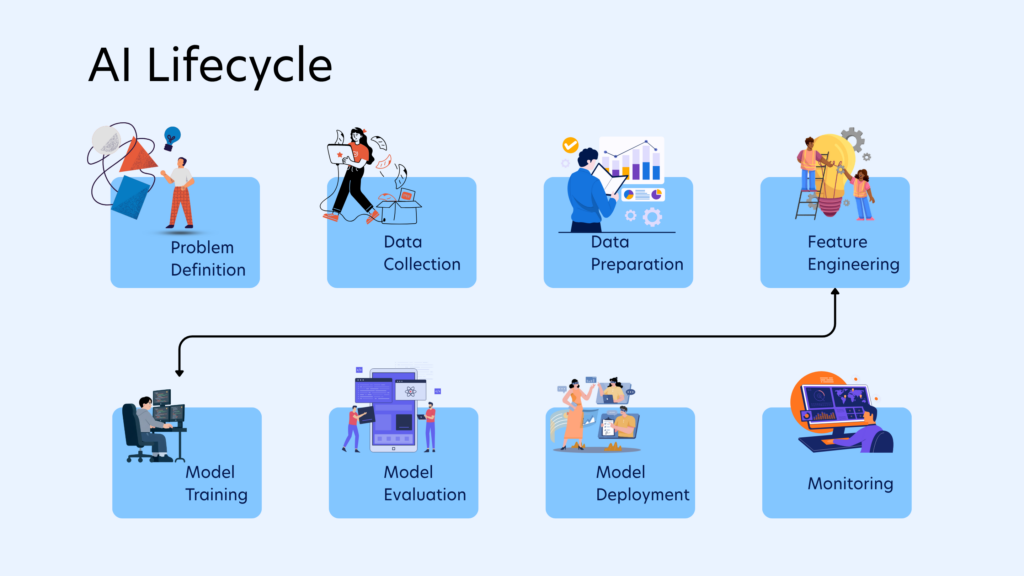
The Role of Synthetic Data Across the AI Lifecycle
AI lifecycle refers to the end-to-end process of designing, developing, deploying, and continuously improving artificial intelligence systems. It encompasses every stage involved in transforming raw data into intelligent models that can generate predictions, automate decisions, or perform complex tasks.
Synthetic data fundamentally changes where and how data contributes across this AI lifecycle. Instead of being confined to the early stages of collection and preparation, data becomes an active, evolving component across the entire lifecycle, which is why even Gartner estimates that by 2030 synthetic data will overshadow real data in AI models completely.
In the ideation phase, synthetic data enables teams to explore possibilities before real data even exists.
Want to test a fraud detection concept in a new market? You can simulate transaction patterns.
Curious about how a model might behave under extreme conditions? You can generate those conditions from scratch.
As development progresses, synthetic data supports iterative experimentation. Teams can design datasets tailored to specific hypotheses adjusting distributions, introducing anomalies, or isolating variables.
In production, synthetic data continues to play a role by helping models adapt to changing environments. It allows for continuous learning without relying solely on newly collected real-world data.
This represents a deeper shift—from data dependency to data design. Instead of asking, “What data do we have?” organizations begin asking, “What data do we need?” That mindset unlocks a far more proactive and strategic approach to AI.
1. Accelerating Model Training and Experimentation
Speed matters in AI development. The ability to iterate quickly often determines whether a project succeeds or stalls. This is where synthetic data enables faster iteration by removing the dependency on static datasets.
- Need to test a new feature? Generate a dataset.
- Want to explore how your model handles skewed distributions? Adjust the parameters and regenerate.
This flexibility compresses development cycles significantly.
Beyond speed, synthetic data enhances robustness. Models trained on narrowly defined real-world datasets tend to overfit—they perform well on known patterns but struggle with variation. Synthetic data introduces controlled variability, helping models generalize better.
Bias is another critical area. Real-world data often encodes historical inequalities or systemic biases. Synthetic data allows teams to intervene to rebalance representation, simulate underrepresented groups, and test fairness more rigorously. While it doesn’t automatically eliminate bias, it provides a mechanism to address it proactively.
In this sense, synthetic data doesn’t just accelerate experimentation – it elevates its quality.
2. Enabling Privacy-First and Compliant AI
As AI systems become more pervasive, the stakes around data privacy have risen sharply. Regulations and public expectations are converging toward a single demand: protect sensitive information without slowing innovation.
Synthetic data offers a compelling path forward. Because it is artificially generated, it does not correspond to real individuals, even when it mirrors real-world patterns. This reduces the risk of exposing personally identifiable information or sensitive records.
For industries governed by strict regulations such as healthcare and finance, this is particularly valuable. Synthetic datasets can be used for development, testing, and even collaboration across organizations without violating privacy constraints.
But the impact goes beyond compliance. Synthetic data supports a broader shift toward responsible AI. It encourages organizations to think critically about how data is used, how models are trained, and how risks are mitigated. It aligns technical capability with ethical responsibility.
3. Strengthening Model Validation and Testing
One of the most underestimated challenges in AI is validation. A model that performs well in controlled environments can still fail in the real world often in unpredictable ways.
Synthetic data enhances validation by enabling stress testing at a level that real-world data alone cannot achieve. Teams can simulate extreme conditions, rare events, and entirely novel scenarios to evaluate how models behave under pressure.
This is especially important in high-stakes applications. Whether it’s a medical diagnosis system, a financial risk model, or an autonomous system, failure in edge cases can have serious consequences.
By systematically exposing models to these scenarios before deployment, synthetic data improves reliability and resilience. It helps uncover blind spots early, when they are easier and less costly to address.
4. Operationalizing Synthetic Data at Scale
While the benefits are clear, scaling synthetic data across an enterprise is not trivial. It requires more than tools; it demands a shift in how data is governed and integrated.
One challenge in this context is ensuring quality. Synthetic data must accurately reflect the statistical properties of real-world data while avoiding artefacts that could mislead models. This requires robust generation techniques and validation frameworks.
Integration is another hurdle. Synthetic data must fit seamlessly into existing MLOps pipelines—feeding into training workflows, evaluation systems, and deployment processes without friction.
Governance is equally critical. Organizations need visibility into how synthetic data is generated, how it evolves, and how it impacts model performance. This includes tracking lineage, enforcing standards, and continuously monitoring outcomes.
Successfully operationalizing synthetic data means treating it as a first-class component of the AI lifecycle not an experimental add-on.
How Everforth Quinnox AI (EQAI) Studio Is Making Synthetic Data Generation Seamless
As enterprises navigate these challenges, platforms like Everforth Quinnox AI (EQAI) Studio are emerging to simplify adoption and scale impact.
EQAI Studio takes an end-to-end approach to synthetic data generation. Rather than focusing solely on data creation, it integrates synthetic data into the broader AI lifecycle – ensuring that it supports ideation, development, validation, and deployment in a cohesive manner.
One of its key strengths lies in accessibility. With low-code and no-code capabilities, EQAI Studio enables both technical and non-technical users to generate and work with synthetic data. This democratizes data design and accelerates cross-functional collaboration.
Furthermore, governance is built into the platform. Automated quality checks, compliance safeguards, and lifecycle tracking ensure that synthetic data meets enterprise standards. This reduces risk while maintaining flexibility.
Ultimately, EQAI Studio helps organizations move faster without compromising control – shortening time-to-value while lowering the barriers to AI adoption.
Real-World Use Cases and Industry Applications of Synthetic Data
Synthetic data is already delivering tangible value across industries, often in ways that were previously impractical.
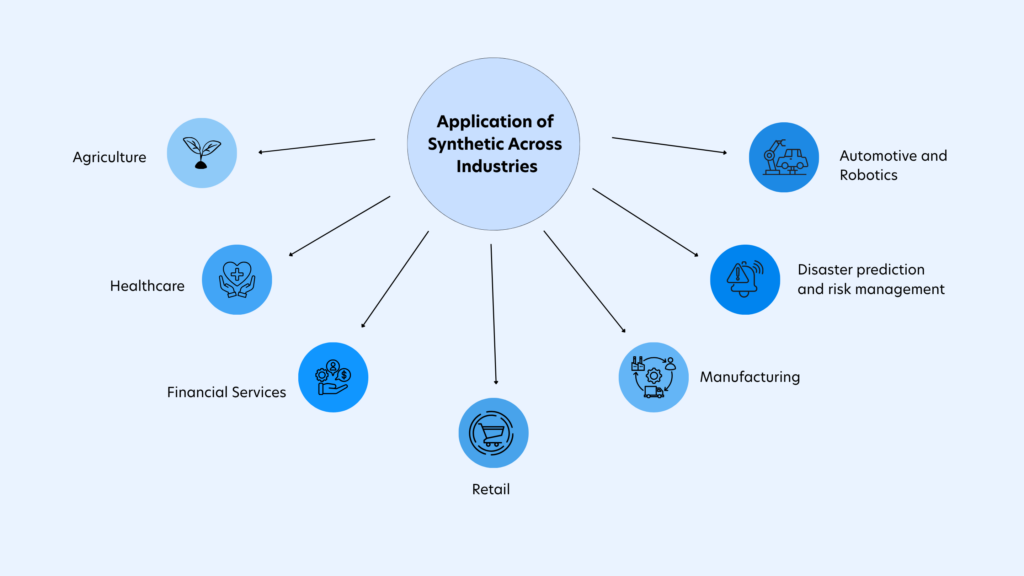
Financial Services
Banks and financial institutions use synthetic data to:
- Detect fraud patterns
- Simulate transaction anomalies
- Improve risk modeling
- Train AI without exposing customer information
Synthetic datasets help institutions enhance cybersecurity and compliance simultaneously.
Healthcare
Healthcare organizations leverage synthetic data to:
- Train diagnostic models
- Simulate patient populations
- Advance drug discovery
- Support medical imaging AI
This enables innovation while protecting patient privacy.
Retail
Retailers use synthetic data for:
- Demand forecasting
- Customer behavior analysis
- Personalized recommendations
- Inventory optimization
Synthetic consumer behavior simulations help retailers improve customer experiences and operational efficiency.
Manufacturing
Manufacturers generate synthetic sensor and operational data to:
- Predict equipment failures
- Optimize production lines
- Improve quality control
- Enhance industrial automation
Synthetic industrial data supports predictive maintenance and smart factory initiatives.
Across sectors, synthetic data is enabling organizations to innovate faster while reducing operational constraints.
The Future of Synthetic Data in AI
We are also seeing the rise of synthetic data as a strategic asset. Organizations are beginning to invest in domain-specific data generation capabilities, creating datasets that reflect their unique operational environments. This is becoming a source of competitive differentiation.
Several trends are shaping this future.
Generative AI Advancements
Advances in generative models are improving the realism and complexity of synthetic datasets across text, image, video, and structured data domains.
AI Governance and Responsible AI
As governments introduce stricter AI regulations, synthetic data will become increasingly important for privacy-preserving and ethically aligned AI development.
Digital Twins and Simulation
Organizations are combining synthetic data with digital twins to simulate entire operational environments for predictive analytics and intelligent automation.
Autonomous Systems
Autonomous vehicles, robotics, and industrial AI systems will rely heavily on synthetic environments for training and validation.
Real-Time Synthetic Data Generation
Future AI systems may dynamically generate synthetic data in real time to continuously improve learning and adaptation.
The organizations that embrace synthetic data today are positioning themselves for the next era of scalable and responsible AI innovation.
Conclusion: From Data Constraints to AI Possibility
AI innovation has long been constrained by data—its availability, its quality, and its limitations. Synthetic data offers a way to move beyond those constraints.
By enabling organizations to design, generate, and refine data with intent, it transforms the AI lifecycle. It accelerates development, improves model performance, enhances privacy, and supports responsible innovation.
More importantly, it changes how organizations think about data not as a static resource to be collected, but as a dynamic capability to be engineered.
This marks a profound shift in the future of AI.
The conversation is no longer: “Do we have enough data to build better AI?”
The new question is: “Are we creating the right data to build more intelligent, ethical, and future-ready AI systems?”
Organizations that embrace this shift will not only accelerate AI innovation but also build systems that are more adaptive, trustworthy, and resilient in an increasingly data-driven world.
And in many ways, that is where the next era of AI truly begins.

VP, AI & Data, Everforth Quinnox
FAQs
Synthetic data is artificially generated data that replicates the statistical patterns and characteristics of real-world data without directly copying actual records. It is used to train, test, and validate AI models while reducing dependency on sensitive or limited real datasets.
AI systems require massive amounts of high-quality data to perform effectively. However, real-world data is often expensive, incomplete, biased, or restricted by privacy regulations. Synthetic data helps organizations overcome these limitations by providing scalable, customizable, and privacy-safe datasets.
Synthetic data contributes across the entire AI lifecycle, including:
– Data collection and preparation
– Model training
– Testing and validation
– Bias reduction
– Privacy compliance
– Continuous model improvement
It enables faster experimentation and more resilient AI systems.
Synthetic data supports compliance with regulations such as GDPR, HIPAA, and CCPA by minimizing exposure to sensitive customer or patient information while still enabling AI model development, testing, and collaboration.
Common challenges include:
– Ensuring data realism and quality
– Building trust in synthetic datasets
– Integrating with existing AI pipelines
– Governance and compliance management
– Scaling synthetic data generation across enterprises
Synthetic data allows organizations to simulate edge cases, rare events, and high-risk scenarios that are difficult to capture in real-world datasets. This strengthens model reliability, fairness, and performance before deployment.