Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
Every day, companies worldwide face an impossible choice: innovate with data or protect privacy. But what if this choice was a false dilemma?
While most organizations still struggle with this paradox, a quiet revolution is reshaping how we think about data which why Gartner estimates that by 2030 synthetic data will overshadow real data in AI models completely. The market further reflects this shift with the global synthetic data generation market expected to reach $5 billion by 2035 from $1.27 billion, growing at a compound annual growth rate (CAGR) of 12.14%.
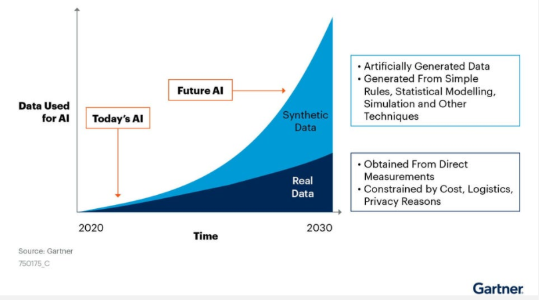
This isn’t just another tech trend; it’s becoming the backbone of modern AI development, offering companies both innovation and privacy protection.
The Data Dilemma Organizations Face Today
In today’s data-driven world, organizations face a paradox: they need more data to fuel their AI and machine learning models, yet they’re constrained by privacy regulations, data scarcity, and security concerns. This challenge has given birth to one of the most revolutionary solutions in recent years – AI-generated Synthetic Data.
Far from being a mere academic concept, synthetic data has emerged as a practical necessity for companies looking to innovate without compromising privacy or security. Initially developed to support researchers working with confidential datasets, AI-generated synthetic data generation now plays a central role in reshaping data strategies across industries. By producing realistic, privacy-safe alternatives to real data, it empowers organizations to build, test, and deploy intelligent systems at scale — responsibly and securely.
What is Synthetic Data?
Synthetic data refers to artificially created datasets that closely replicate the characteristics and patterns of real-world information. Instead of capturing actual user data, synthetic data is produced using advanced algorithms such as statistical models, deep learning, and generative AI techniques. Essentially, it acts as a digital replica of your original data, mirroring its structure and behavior without containing any real personal or sensitive details.
What makes synthetic data particularly valuable is its ability to deliver the benefits of real data while sidestepping privacy issues. According to experts in the field, synthetic data is generated to supplement or substitute genuine datasets, enhancing the training of AI models, safeguarding confidential information, and reducing biases.
Traditional anonymization methods tend to obscure or delete sensitive details from data, but often leave enough traces that could be exploited. In contrast, synthetic data involves crafting entirely new data points that preserve the underlying statistical relationships and correlations. This enables data scientists and analysts to run accurate simulations, tests, and machine learning processes just as they would with authentic data but without compromising privacy.
A crucial advantage of synthetic data is that it contains no direct links to real individuals or entities. Its generation process ensures privacy by design, making it nearly impossible to trace back to original sources. The growing adoption of synthetic data is evident in initiatives like Microsoft’s Phi-4 language model, which was primarily trained on synthetic datasets, showcasing the rising trust in this innovative approach to data privacy and AI development.
The Different Types of Synthetic Data
Understanding the types of synthetic data helps organizations choose the right approach for their needs:
By Data Format

Tabular Data: This type of data is organized into rows and columns, making it perfect for databases and spreadsheets. It’s commonly used in areas like customer records, transaction logs, and business analytics. Because of its structured nature, generating synthetic tabular data that preserves the original statistical patterns is relatively straightforward and highly effective.
Text Data: Textual data covers a wide range of natural language content from customer feedback to detailed technical manuals. This technique allows businesses to build realistic conversational datasets, such as for chatbot development, without risking exposure of sensitive or proprietary information.
Multimedia Data: This includes images, videos, and other forms of unstructured data essential for computer vision tasks like object recognition and image classification. Thanks to breakthroughs in generative AI, it’s now possible to produce highly convincing synthetic multimedia content. These datasets can effectively train vision models while avoiding privacy concerns tied to using real-world images or videos.
By Synthesis Level
Fully Synthetic Data: Here, all data points are artificially generated from scratch without relying on actual records. This approach models the underlying patterns, distributions, and relationships found in real data to create a close approximation. For example, financial firms such as J.P. Morgan generate synthetic samples of fraudulent transactions to enhance AI-based fraud detection, overcoming the scarcity of authentic suspicious data.
Partially Synthetic Data: In this method, real datasets serve as the foundation, but sensitive fields are replaced or masked with artificial values. This strategy balances the need for authenticity with privacy protection, making it especially useful in areas like healthcare research, where maintaining the integrity of clinical data is critical but patient confidentiality must be preserved.
Hybrid Synthetic Data: Hybrid data merges genuine records with synthetic ones, combining real and artificial entries within a dataset. By mixing these elements, organizations can analyze customer data and extract insights without risking the disclosure of personally identifiable information or sensitive details.
Synthetic Data Generation Techniques: How Is Synthetic Data Actually Made?
Synthetic data isn’t pulled from a database – it’s built, from the ground up, using sophisticated techniques that model and mimic real-world data. These methods range from simple rule-based logic to complex neural networks. Here’s how it’s done:
1. Statistical Modeling
This classic technique relies on analyzing patterns, distributions, and relationships in a real dataset. Once these statistical properties are understood, algorithms generate new data that closely reflects the original dataset’s structure. While this method is fast and transparent, it may fall short when trying to replicate intricate, non-linear data behaviors common in real-world systems.
2. Generative Adversarial Networks (GANs)
GANs are a game-changer in synthetic data creation. They involve two neural networks playing a digital cat-and-mouse game: one generates synthetic samples, and the other tries to detect whether the data is real or fake. Over time, this feedback loop trains the generator to produce synthetic data that’s nearly indistinguishable from actual records.
3. Variational Autoencoders (VAEs)
VAEs offer a more structured approach to deep learning-based data generation. They work by encoding input data into a compressed representation and then decoding it back into a new, synthetic version. VAEs are well-suited for generating data that retains the broad statistical properties of the original dataset while introducing safe variations.
4. AI Language Models
Advanced language models, like ChatGPT and others, can generate synthetic text data by learning the structure and semantics of human language. Platforms such as Microsoft Azure AI Foundry now allow businesses to harness these models to create high-quality synthetic datasets—ideal for training chatbots, sentiment analysis engines, or NLP-based applications—without risking exposure of sensitive data.
5. Rule-Based Systems
This method generates data based on custom business rules or logical conditions. For example, if a company knows that customers aged 25–35 are likely to buy a certain product, it can create synthetic records that reflect that behavior. Rule-based generation is highly controllable and ideal for domains like finance or healthcare where regulations demand precision and traceability.
Key Benefits of Synthetic Data Generation
The adoption of synthetic data generation isn’t just driven by privacy concerns – it offers a comprehensive set of advantages that address multiple business challenges simultaneously.
Privacy Protection without Compromise
As privacy regulations like GDPR, CCPA, and HIPAA grow stricter, the challenge of using real-world data without breaching compliance continues to intensify. Synthetic data offers a powerful solution, enabling organizations to extract insights and drive innovation without exposing any actual personal or sensitive information.
Whether it’s sharing data with external partners, conducting research, or testing applications, synthetic datasets allow businesses to stay compliant while remaining agile.
Unlimited Data on Demand
One of the biggest bottlenecks in AI development is acquiring clean, labeled, real-world data especially for rare events or edge cases. Synthetic data removes that barrier by providing on-demand generation of any data type or volume.
Enhanced Security
Unlike real datasets that carry risks if exposed, synthetic data is inherently secure because it contains no actual user or operational data. Even if breached, synthetic records reveal nothing of value, drastically reducing the risk associated with internal testing, model training, or sharing datasets across environments.
Build Secure and Compliant AI Models
Synthetic data plays a vital role in building secure, regulation-ready AI models. It allows teams to simulate real-world conditions including rare and sensitive scenarios without using actual customer data. This supports safe, ethical model development and reduces compliance overhead during audits or validation.
Cost Efficiency
Instead of investing in complex data collection system or purchasing third-party datasets, businesses can use synthetic data to cut costs on storage, procurement, and data handling. This is especially beneficial for mid-sized enterprises and start-ups that need flexible, scalable access to quality data without the high price tag.
Accelerated Development and Testing
Both the development and QA teams benefit greatly from the speed and specificity that synthetic test data offers. Instead of waiting on production datasets or compromising tests due to data gaps, they can instantly generate exactly what’s needed, accelerating cycles for testing, optimization, and feature rollout.
Risk Mitigation
Beyond compliance, synthetic data minimizes operational and reputational risks. Testing in controlled environments ensures that bugs, errors, or failures don’t affect live systems or real users, empowering teams to explore, iterate, and innovate freely.
Synthetic Data Use Cases Across Industries
The versatility of synthetic data has led to its adoption across virtually every industry, each finding unique applications that address specific challenges.
1. Technology & Software Development
In the world of app development and AI, testing with real user data can create major privacy concerns. Tech firms now use synthetic data to simulate real user behavior, build demo environments for sales pitches, and train ML models safely. Innovation hub like Quinnox AI (QAI) Studio exemplify how big players are making it easier for businesses to deploy AI faster and more affordably using synthetic datasets in just days and not months.
2. E-commerce & Retail
Online retailers are tapping into synthetic data to model consumer behavior, streamline inventory, and detect fraudulent transactions. For example, synthetic purchase data can help test fraud detection systems without ever touching actual customer records, ensuring compliance and safeguarding consumer trust.
3. Manufacturing & Industry
Factories and production facilities are generating synthetic IoT sensor data to power predictive maintenance, enhance quality checks, and fine-tune supply chains. These datasets are further allowing engineers to train models and run simulations without risking exposure of sensitive proprietary data or operations.
4. Autonomous Systems & Robotics
Autonomous vehicles, drones, and robots rely on data-rich environments to learn and operate. Synthetic data makes it possible to train these systems safely and at scale. As edge computing grows, Gartner estimates that over 55% of deep learning will happen on-device by 2025—amplifying the need for reliable, realistic synthetic data in edge AI environments.
5. Gaming & Digital Entertainment
Game developers are generating synthetic user interactions to test new features and analyze player behavior without affecting real gameplay experiences. Synthetic data also supports content generation and balancing, helping teams build better games faster and more ethically.
6. Cloud & Infrastructure
As demand on digital infrastructure rises, synthetic data plays a key role in optimizing resource allocation and planning. With tech giants like Microsoft investing over $80 billion into AI-driven data centers, synthetic data is essential in running simulations, load testing, and scaling operations efficiently and securely.
7. Financial Services
Banks, fintechs, and insurers are turning to synthetic transaction data to train fraud detection models, validate risk algorithms, and test compliance systems. These datasets enable safe experimentation without exposing actual customer information—critical in highly regulated environments.
Limitations and Challenges of Synthetic Data
While synthetic data offers tremendous benefits, it’s not perfect. Here are the main challenges:
1. Replicating Real-World Complexity Isn’t Easy
Generating synthetic data that truly mimics real-world data is a demanding task. If done poorly, it can introduce distortions, leading to misleading insights and skewed AI outputs. Ensuring quality and realism in synthetic datasets requires thoughtful design and rigorous validation.
2. Heavy Computing Demands
High-fidelity synthetic data especially when dealing with unstructured formats like video, audio, or images—requires serious processing power. Training models like GANs or VAEs at scale is resource-intensive, often translating into high infrastructure costs and longer development cycles.
3. Difficult to Validate Quality
Unlike traditional datasets where accuracy can be benchmarked against ground truth, synthetic data lacks a clear baseline. Assessing its quality involves advanced validation techniques, including statistical similarity checks and model performance testing—methods many organizations are still learning to implement effectively.
4. Bias May Persist or Get Worse
Synthetic data is only as good as the source it’s modeled after. If the original data is biased, those biases can be preserved or even exaggerated by generative algorithms. Mitigating this requires intentional bias audits and ethical oversight throughout the synthetic data lifecycle.
5. Rare Scenarios May Be Overlooked
AI systems frequently face challenges when dealing with rare or unusual scenarios. Unfortunately, synthetic data generators may also fail to capture these rare but critical situations. Without specific tuning, datasets might lack the diversity needed for robust, real-world performance.
6. Should Complement, Not Replace, Real Data
While synthetic data is a powerful tool, it shouldn’t be treated as a complete substitute for real-world data. The most effective strategies combine both using synthetic data to enhance training, fill gaps, or simulate rare scenarios, while relying on real data for validation and final deployment.
The Future is Synthetic
The synthetic data revolution isn’t coming – it’s here. As privacy regulations tighten and AI models become more sophisticated, synthetic data offers the perfect solution to the innovation-privacy paradox. Companies that embrace synthetic data generation today will find themselves ahead of the curve, building better AI systems while maintaining the highest standards of privacy and security.
The question isn’t whether synthetic data will become mainstream; it’s whether your organization will be ready to harness its power.
Final Thoughts
Synthetic data represents a fundamental shift in how businesses think about data usage and privacy. More than a technical fix, it’s a business strategy that enables innovation while protecting people’s privacy.
Whether you’re a startup looking to test new ideas or an established organization wanting to improve AI models, synthetic data offers a path forward that wasn’t available just a few years ago. And, in this journey, Quinnox’s Gen AI and Data-Driven Intelligence services can be your trusted partner.
If your organization is ready to embrace synthetic data as a catalyst for innovation? Reach our data experts today!
FAQs Synthetic Data Generation
Yes, properly generated synthetic data contains no real personal information and is privacy-preserving by design.
No, synthetic data should complement real data rather than replace it completely for most applications.
Quality varies based on generation techniques and use case, but high-quality synthetic data can closely mirror real data patterns.
Maintaining data quality and fidelity while preserving statistical relationships and patterns from the original dataset.
Time varies from minutes for simple tabular data to hours or days for complex image or video datasets.
Basic synthetic data generation can be done with user-friendly tools, but complex applications require data science expertise.
Yes, synthetic data can help meet privacy regulations, but organizations should verify compliance with legal experts.