Incidents are no longer rare disruptions—they’re business as usual in the digital world. Gartner reports that the average cost of IT downtime is $5,600 per minute—that’s over $300,000 per hour of lost productivity, sales, and customer trust.
Quick Stat: On average, companies report 86 outages per year – translating to 324 minutes of weekly downtime. That’s more than 5 hours lost—every single week.
What’s more alarming is that according to Uptime Institute survey, 60% of significant downtime incidents are preventable with better management, yet many organizations continue to rely on outdated, manual, and siloed incident response processes.
In an era dominated by hybrid clouds, microservices, and 24/7 digital expectations, the traditional “war room” approach is simply not enough. IT teams are overwhelmed by alert storms, fragmented data, and sluggish root-cause identification. It’s no wonder that according to ScienceDirect study, only 10% of U.S. companies have effective incident response capabilities
This blog explores the often-overlooked challenges that silently erode your incident response effectiveness—and more importantly, how to tackle them with proactive, intelligent, and collaborative strategies. Because incidents may be inevitable—but chaos doesn’t have to be.
8 Critical Incident Management Challenges & How to Overcome Them
Before we dive into the eight critical challenges, it’s important to understand why they matter so much. The following chart illustrates the real business impact of poor incident management—from increased costs to customer churn:
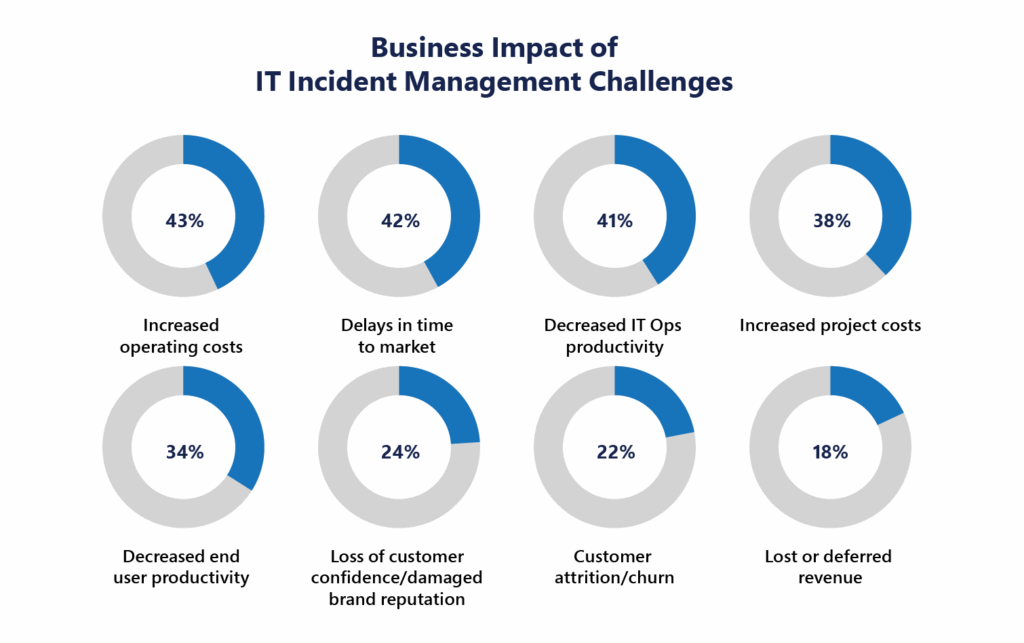
Source: Help Net Security
As you can see, the fallout from mismanaged incidents is more than just technical—it’s financial, operational, and reputational. Let’s break down the hidden incident management challenges that cause these impacts, and how you can address them head-on.
1. Delayed Incident Detection
One of the most pressing issues in incident management is the time it takes to detect a problem. The 2022 IBM Cost of a Data Breach Report revealed that it takes an average of 277 days to identify and contain a breach. This delay can lead to a domino effect of damage, including financial losses, compromised customer data, and reputational harm. Many organizations rely on outdated monitoring systems or inconsistent detection protocols, allowing threats to go unnoticed until they’ve escalated significantly.
Solution:
- Implement Real-Time Monitoring: Utilize advanced monitoring tools that provide real-time alerts to detect anomalies promptly.
- Automate Detection Processes: Incorporate automated systems that can identify and flag irregularities without manual intervention.
- Regular Audits and Updates: Conduct periodic system audits and ensure that detection protocols are up to date to adapt to evolving threats.
2. Ineffective Communication During Incidents
During an incident, the lack of clear and effective communication can escalate an already tense situation. Without predefined channels and responsibilities, teams may duplicate efforts, miss critical steps, or make conflicting decisions. This chaos not only delays resolution but also erodes trust among stakeholders and external partners. In high-stress scenarios, clarity and speed of communication are paramount to control the impact and coordinate recovery efforts.
Solution:
- Use centralized communication platforms like Slack, Microsoft Teams, or sbnsoftware.com to consolidate messages.
- Create a communication playbook that outlines who communicates what and to whom.
- Schedule cross-departmental incident response drills to ensure everyone understands roles and expectations.
- Utilize incident command systems (ICS) frameworks to streamline hierarchy during crises.
3. Lack of Standardized Processes
In the absence of standardized incident response processes, teams often rely on ad-hoc methods to manage crises. This inconsistency results in varying response quality, overlooked procedures, and missed documentation. Without clear guidance, even experienced professionals may struggle to handle incidents effectively, especially under pressure. The lack of structure can also make post-incident analysis difficult, reducing opportunities to learn and improve.
Solution:
- Develop Comprehensive Incident Response Plans: Create detailed procedures outlining steps to be taken during various types of incidents.
- Implement Frameworks: Adopt industry-standard frameworks like ITIL to guide incident management practices.
- Continuous Improvement: Regularly review and update processes based on lessons learned from past incidents.
4. Insufficient Training and Awareness
A well-designed incident management plan is only effective if the people responsible for executing it are trained and aware of their roles. Unfortunately, many employees, especially those outside of IT, are unaware of how to recognize or report potential incidents. This can cause delays in response and escalation, allowing issues to worsen. Moreover, in a rapidly evolving threat landscape, static training is quickly rendered obsolete.
Solution:
- Conduct ongoing cybersecurity awareness programs (monthly or quarterly).
- Train staff using interactive simulations and gamified learning platforms.
- Ensure all departments understand how and when to escalate incidents.
- Reward early detection and responsible disclosure behaviors.
5. Overreliance on Manual Processes
Manual processes in incident management can introduce delays, inconsistencies, and human error. When every action—from detection to escalation and resolution—requires manual intervention, the response becomes slow and error-prone. Moreover, during large-scale or simultaneous incidents, relying solely on manual workflows can overwhelm teams and leave gaps in coverage.
Solution:
- Automate Incident Management: Utilize tools that automate detection, alerting, and response workflows to reduce human error and accelerate resolution.
- Integrate Systems: Ensure that incident management tools are integrated with other systems for seamless data flow and coordination.
- Monitor Performance Metrics: Track key performance indicators to assess the effectiveness of automated processes and identify areas for improvement.
6. Inadequate Post-Incident Analysis
Failing to thoroughly analyze an incident after resolution is a missed opportunity for learning and improvement. Without post-incident reviews, the root causes of incidents remain hidden, and teams may repeat the same mistakes. Inconsistent or undocumented reviews also prevent the creation of meaningful metrics and benchmarks for incident management performance.
Solution:
- Conduct Post-Incident Reviews: Analyze the root causes, response effectiveness, and outcomes of incidents to identify lessons learned.
- Document Findings: Maintain detailed records of incidents and analyses to inform future training and process improvements.
- Implement Recommendations: Act on insights gained from analyses to enhance incident management strategies and prevent recurrence.
7. Siloed Teams and Information
When departments operate in silos, collaboration during incidents becomes difficult. Each team may have a piece of the puzzle but lacks access to the full picture. This fragmented approach leads to redundant efforts, miscommunication, and inefficient resource use. It can also slow down incident detection and response, especially in large, complex environments.
Solution:
- Promote Cross-Functional Collaboration: Encourage communication and cooperation between departments to ensure a unified response to incidents.
- Centralize Information Sharing: Implement platforms that allow for real-time sharing of information across teams.
- Align Objectives: Ensure that all departments understand the organization’s incident management goals and their role in achieving them.
8. Neglecting Regular Testing and Drills
A response plan that looks good on paper might fall apart under pressure if it hasn’t been tested in real-world scenarios. Without regular testing, organizations cannot gauge their readiness, identify procedural flaws, or build team confidence. When a real incident occurs, the absence of practice can lead to panic, confusion, and avoidable mistakes.
Solution:
- Schedule tabletop exercises, red teaming, and disaster recovery drills quarterly.
- Simulate real-world scenarios like ransomware attacks, system outages, or insider threats.
- Involve senior leadership in simulations to emphasize the importance.
- Update response plans based on drill outcomes.
Identifying and understanding the challenges of incident management is only the beginning. The real transformation begins when organizations invest in the right tools and partners to tackle these issues head-on.
This is where the choice of your technology partner becomes critical. You need more than just another dashboard or rule-based alert system—you need a platform that evolves with your ecosystem, learns from incidents, and orchestrates outcomes across silos.
A strategic partner brings not just tools but capabilities:
- Expertise in AI and automation
- Cross-industry implementation experience
- Capability to integrate across hybrid environments
- Data-driven insights and continuous optimization
And when it comes to checking all those boxes, Qinfinite’s Intelligent Incident Management emerges as the frontrunner.
Why Qinfinite Is the Smart Choice for Intelligent Incident Management
Aspect |
Traditional Testing |
Chaos Engineering |
| Primary Goal | Validate functional correctness of code and features | Validate system resilience under unpredictable and adverse conditions |
| Environment | Mostly runs in development or staging environments | Often runs in production or production-like environments (with safeguards) |
| Scope of Failures | Tests known scenarios like missing inputs, invalid formats | Tests unknown unknowns like service failures, latency spikes, and node crashes |
| Failure Type Simulated | Code-level bugs, unit test failures, API contract violations | Real-world incidents: disk failure, API timeout, network partition, traffic surge |
| Testing Philosophy | Assumes the environment is stable and controlled | Assumes that failures are inevitable and should be proactively tested |
| Experimentation Model | Static test cases with predefined inputs/outputs | Hypothesis-driven experiments with observable impact on system behavior |
| Blast Radius | No concept of blast radius | Introduces concept of blast radius to control experiment impact |
| Observability Need | Moderate observability — logs and some basic metrics | Heavy reliance on observability — metrics, traces, alerts are crucial |
| Metrics Focus | Focuses on test pass/fail criteria | Focuses on latency, error rates, throughput, availability, UX impact |
| Change Trigger | Runs automatically during builds or deployments | Triggered as controlled, planned experiments by SRE or DevOps teams |
| Risk Coverage | Covers expected failures | Covers unexpected, cascading, systemic failures |
| Business Impact | Validates business rules and feature compliance | Protects customer experience and SLAs under failure conditions |
| Feedback Loop | Feedback mostly confined to QA cycles | Feedback drives resilience engineering, architecture, and runbooks |
| End Goal | Ensure code quality | Ensure system reliability and operational readiness |
Imagine an incident management solution that doesn’t just react to problems—but foresees them, learns from them, and helps you avoid them altogether. That’s exactly what Quinnox’s intelligent application management, Qinfinite offers.
Here’s how Qinfinite helps address each of the previously mentioned challenges, turning obstacles into strategic opportunities:
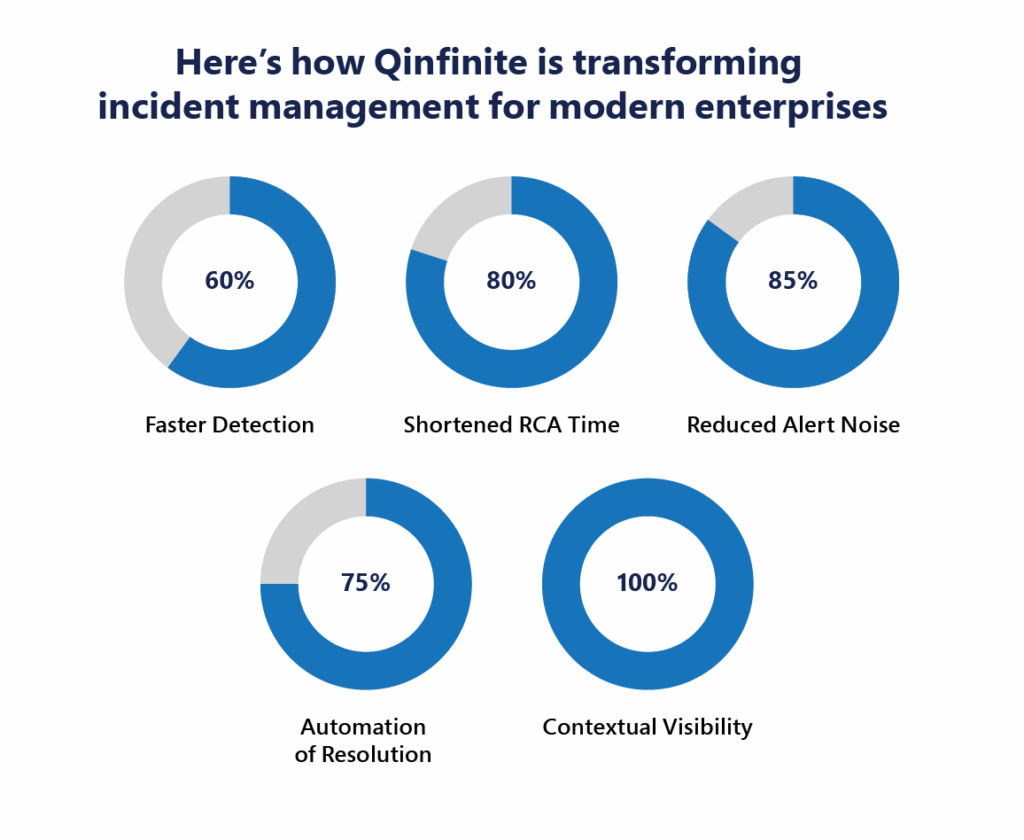
- Early Detection Through AI-Powered Monitoring: Qinfinite harnesses machine learning algorithms to detect anomalies in real-time, reducing mean time to detect (MTTD) by up to 60%. This enables early alerts before customers are impacted, minimizing downtime and improving trust.
- Streamlined, Cross-Channel Communication: With centralized communication hubs and smart escalations, Qinfinite keeps everyone—from DevOps to CXOs—informed, connected, and aligned during every incident lifecycle.
- Standardization Without Rigidity: Qinfinite allows organizations to customize incident playbooks that are both standardized and flexible. AI suggestions evolve over time, ensuring best practices adapt to your growing environment.
- Workforce Empowerment with AI: Empower teams to focus on innovation instead of incident drudgery. Qinfinite’s no-code automation workflows eliminate repetitive manual work, giving back time to your IT teams.
- Alert Noise Reduction by 85%: One of Qinfinite’s standout features is its AI-powered alert deduplication and root cause correlation, filtering out false positives and grouping related alerts. This has helped enterprises reduce alert fatigue by up to 85%, according to internal performance benchmarks.
- Self-Learning Post-Mortems: Post-incident analysis is where learning lives. Qinfinite automates root cause analysis (RCA) and learns from each outage, feeding insights into future incident prevention.
- Unifying Disparate Teams Through One Command Center: Modern businesses struggle with silos. Qinfinite creates a single source of truth across monitoring tools, ticketing systems, and knowledge bases. With built-in collaboration features, cross-functional teams operate like a single unit—no more war rooms, just one collaborative, intelligent platform.
The Numbers Speak for themselves
Final Thoughts
Incident management challenges aren’t going away. But how you respond to them can make all the difference between surviving and succeeding. By recognizing the overlooked challenges and aligning with a platform like Qinfinite, you’re not just improving your incident response—you’re elevating your entire IT strategy.
Ready to Experience Proactive, Intelligent Incident Management? Book a FREE Consultation with Qinfinite experts to see how we can help transform your incident management strategy.
FAQ’s Related to Incident Management Challenges
Commonly missed challenges include lack of proper documentation, unclear escalation paths, fragmented tooling, and poor prioritization. These issues often lead to slower response times, higher operational risks, and missed learning opportunities from past incidents.
Collaboration often breaks down due to siloed communication, inconsistent tooling, and unclear responsibilities. High-stress environments make alignment harder, and without a unified incident response framework, teams waste valuable time coordinating instead of resolving.
Without defined ownership, incidents suffer from delayed responses, duplicated efforts, and finger-pointing. It creates confusion around accountability and escalations, which in turn prolongs downtime and frustrates both teams and customers.
Poor incident management leads to increased operational costs, delayed product releases, and lower IT productivity. It can damage brand reputation, result in customer churn, and directly impact revenue—as reflected in the image highlighting key business impacts.
Automation helps by speeding up incident detection, streamlining alerts, and reducing manual steps in resolution. It ensures faster response times, minimizes errors, and allows teams to focus on complex problem-solving rather than repetitive tasks.
PIRs enable teams to analyze root causes, identify process gaps, and implement preventive measures. They foster a culture of continuous learning and help in building more robust incident response strategies for future resilience.