Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
It was just a routine deployment. What could possibly go wrong?
The SRE team at a global fintech firm rolled out a small code change during a Friday evening deployment. Moments later, customers started reporting errors accessing their accounts. Transactions failed, the app lagged, and within minutes, the service reliability metric dropped by 45%. The root cause? A database failover that hadn’t been tested under real-world failure conditions. And the worst part? The team had no playbook ready—just dashboards going red.
This isn’t a one-off. According to an industry report (IBM), the average cost of an unplanned outage is $4.45 million, and 83% of organizations experience more than one breach or incident. For today’s DevOps and SRE teams, system failure is not a question of if but when.
That’s where Chaos Engineering becomes not just useful, but essential. It’s not about breaking things for fun—it’s about learning how systems behave under stress and how teams respond to failure. For DevOps and SRE, it offers a strategic pathway to build more reliable, robust, and self-healing systems.
A recent survey found that 48% of M&A professionals are now using AI in their due diligence processes, a substantial increase from just 20% in 2018, highlighting the growing recognition of AI’s potential to transform M&A practices.
What is Chaos Engineering in SRE and DevOps?
Chaos Engineering is the deliberate practice of introducing failures into a system to test its ability to recover and maintain stability under stress. Contrary to its name, it’s not about causing chaos—it’s about understanding and controlling it.
The concept gained traction when American video streaming platform, Netflix introduced Chaos Monkey, a tool that randomly killed instances in production to ensure their services could self-heal and remain available.
Think of it like a fire drill for software systems — instead of waiting for the data center to go down or a critical service to crash during peak traffic, teams simulate these scenarios in a safe way to discover weaknesses before customers feel the impact.
But Chaos Engineering is more than just breaking things for fun. It’s a scientific, data-driven approach rooted in discipline and learning.
In the DevOps world, where speed and agility are top priorities, chaos engineering ensures that systems can withstand the pace of rapid code deployments, infrastructure changes, and constant scaling.
And for SRE teams, whose North Star is reliability, chaos engineering is the ultimate resilience validation tool. It helps SREs move from reactive firefighting to proactive reliability assurance — aligning perfectly with Google’s SRE ethos of “Hope is not a strategy.”
Core Principles of Chaos Engineering
Chaos Engineering follows a structured methodology that ensures safety, predictability, and learning. Here are its six foundational principles:
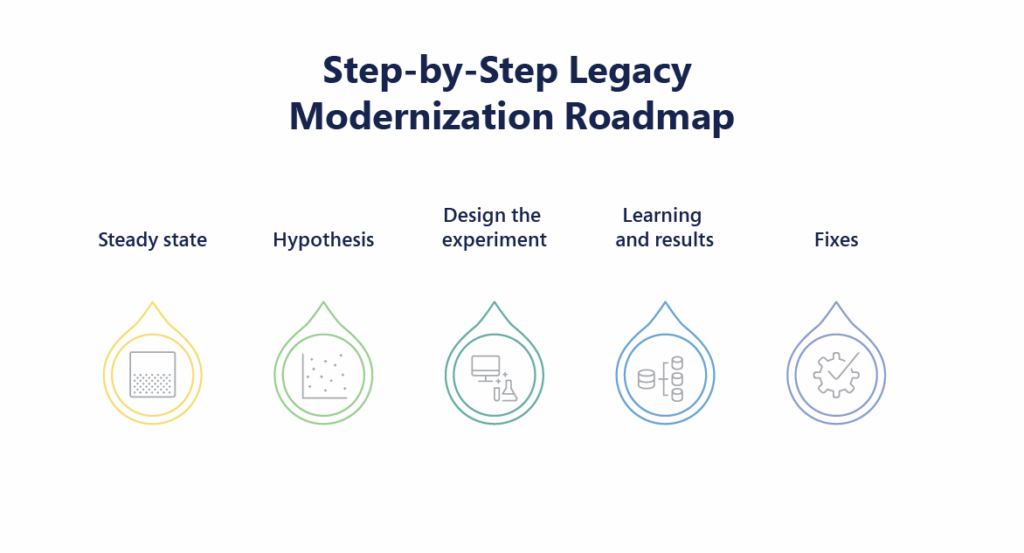
1. Build a Hypothesis Around Steady State
Before introducing failure, define what normal behavior looks like. This could be metrics like request throughput, latency, or error rate. For example: “Under normal conditions, our checkout service processes 500 requests per second with <1% error rate.” This gives you a baseline to measure any impact caused by your chaos experiment.
2. Vary Real-World Events
Chaos tests should simulate real-world failure conditions — like instance crashes, high CPU usage, DNS failures, or region-wide outages. The closer these tests are to real-world scenarios, the more useful they become. Example: Inject 300ms latency between two services to simulate a network hiccup in a cloud region.
3. Run Experiments in Production (Carefully)
While it’s common to start in staging, true chaos engineering eventually tests production — where real users and dependencies exist. However, this must be done cautiously, with:
- Feature flags
- Blast radius controls
- Real-time rollback mechanisms
Companies like Netflix and Amazon famously run chaos experiments in production to validate global failover mechanisms.
4. Minimize Blast Radius
Don’t pull the plug on the whole system. Start small — target one pod, one API, one region. Gradually increases the complexity as confidence grows.
5. Automate and Integrate
Chaos Engineering becomes most powerful when it’s automated and integrated into DevOps pipelines or SRE routines. This makes resilience validation part of everyday operations — not a one-time project. Run chaos tests nightly as part of your regression suite.
6. Learn and Improve Continuously
Every chaos experiments should produce data, insights, and action items. Did the alert fire? Did the fallback work? Was the team notified? The goal isn’t just to survive failure — it’s to learn from it and get stronger.
According to IAEME Research, organizations conducting regular chaos experiments identified an average of 43.5 potential failure modes per quarter, preventing an estimated $2.3 million in potential downtime costs annually.
Chaos Engineering vs. Traditional Testing: A Side-by-Side Comparison
Aspect |
Traditional Testing |
Chaos Engineering |
| Primary Goal | Validate functional correctness of code and features | Validate system resilience under unpredictable and adverse conditions |
| Environment | Mostly runs in development or staging environments | Often runs in production or production-like environments (with safeguards) |
| Scope of Failures | Tests known scenarios like missing inputs, invalid formats | Tests unknown unknowns like service failures, latency spikes, and node crashes |
| Failure Type Simulated | Code-level bugs, unit test failures, API contract violations | Real-world incidents: disk failure, API timeout, network partition, traffic surge |
| Testing Philosophy | Assumes the environment is stable and controlled | Assumes that failures are inevitable and should be proactively tested |
| Experimentation Model | Static test cases with predefined inputs/outputs | Hypothesis-driven experiments with observable impact on system behavior |
| Blast Radius | No concept of blast radius | Introduces concept of blast radius to control experiment impact |
| Observability Need | Moderate observability — logs and some basic metrics | Heavy reliance on observability — metrics, traces, alerts are crucial |
| Metrics Focus | Focuses on test pass/fail criteria | Focuses on latency, error rates, throughput, availability, UX impact |
| Change Trigger | Runs automatically during builds or deployments | Triggered as controlled, planned experiments by SRE or DevOps teams |
| Risk Coverage | Covers expected failures | Covers unexpected, cascading, systemic failures |
| Business Impact | Validates business rules and feature compliance | Protects customer experience and SLAs under failure conditions |
| Feedback Loop | Feedback mostly confined to QA cycles | Feedback drives resilience engineering, architecture, and runbooks |
| End Goal | Ensure code quality | Ensure system reliability and operational readiness |
Why Chaos Engineering is Critical for SRE and DevOps
For SRE’s
1. Resilience Is a Core Tenet of SRE — Chaos Engineering Makes It Testable
SRE isn’t just about firefighting outages — it’s about building systems that won’t fail catastrophically in the first place. However, most systems are too complex to anticipate every failure. Chaos Engineering fills that gap by enabling controlled experiments that deliberately introduce failure — latency spikes, dropped packets, misconfigured DNS, or even instance termination — in a safe environment.
By running these experiments, SRE teams gain data-driven insights into how services react under duress. This proactive approach identifies single points of failure and validates redundancy strategies long before a real-world incident can expose them.
2. Measurable Impact on SLIs/SLOs
Chaos Engineering allows SREs to validate that Service Level Indicators (SLIs) — such as latency, error rate, and availability — remain within acceptable Service Level Objectives (SLOs) even during adverse conditions.
For example, let’s say your SLO dictates 99.99% uptime for a login service. A chaos test might simulate a database outage to check if the fallback cache kicks in. If latency spikes or errors rise sharply, the team knows where to optimize. Without this proactive failure simulation, you might only discover these issues during an actual outage — when stakes are highest.
3. Enables Blameless Learning and Better Incident Preparedness
SRE culture promotes blameless postmortems, focusing on learning over punishment. Chaos Engineering extends this by enabling controlled failure injection that mimics real outages without actual user impact. Teams can practice incident response, tune alert thresholds, and revise runbooks — all without waiting for failure to strike.
Do you know? Companies that practice chaos simulations for incident drills report 30–50% faster MTTR.
4. Reduces Operational Toil with Continuous Resilience Checks
One of SRE’s biggest mandates is toil reduction — minimizing repetitive, manual work. By integrating chaos testing into CI/CD pipelines or nightly jobs, SREs automate the validation of resilience properties. This way, every deployment is chaos-tested before reaching production, reducing the risk of regression-induced outages.
Quick Tip: Use tools like Qinfinite to run chaos tests as part of your deployment cycle.
For DevOps
If SRE is about stability and reliability, DevOps is about speed, automation, and delivering features faster. But speed without resilience is a ticking time bomb. Here’s why Chaos Engineering is a DevOps game-changer.
1. Instills Confidence in Continuous Deployment Pipelines
Modern DevOps workflows rely on CI/CD pipelines for rapid code delivery. But how do you ensure that new builds, features, or infrastructure changes don’t degrade system resilience? Chaos Engineering introduces resilience testing as part of the delivery process — not after.
Example: A fintech firm integrated chaos tool into their CI/CD pipelines to test if their payment APIs could withstand high network latency during peak loads. The experiment revealed improper retry logic — which was fixed before reaching production. That’s proactive DevOps at its finest.
2. Promotes ‘Shift-Left’ Resilience Testing
DevOps encourages teams to “shift left” — bringing testing, security, and reliability earlier into the development process. Chaos Engineering aligns perfectly by enabling developers to test how their microservices behave when dependencies fail, when pods restart, or when memory usage spikes.
By exposing these weaknesses early, teams avoid expensive fixes late in the lifecycle. This fosters resilience by design, not as an afterthought.
3. Strengthens Observability and Monitoring Systems
You can’t fix what you can’t observe. Chaos Engineering stress-tests not just the application, but also the observability stack — logs, metrics, traces, and alerting. When an injected failure occurs, the team can verify if alerts are firing as expected, logs provide meaningful data, and dashboards reflect the incident in real time.
Example: A DevOps team at a logistics platform realized during chaos tests that their alerting rules missed a crucial service degradation because logs were not structured properly. Fixing this led to better real-world observability.
Quick Stat: Organizations that invest in observability report a 40% decrease in time spent on incident resolution.
4. Breaks Down Silos and Fosters Collaboration
DevOps is about culture as much as tooling. Chaos Engineering brings developers, QA engineers, platform engineers, and security teams to the same table. Everyone gains a shared understanding of system behavior under failure.
Running chaos drills together strengthens the DevOps feedback loop — developers learn how their code reacts under fire, while Ops and SRE teams refine mitigation strategies. It’s cross-functional resilience in action.
A Real-World Scenario Walkthrough: Implementing Chaos Engineering Safely
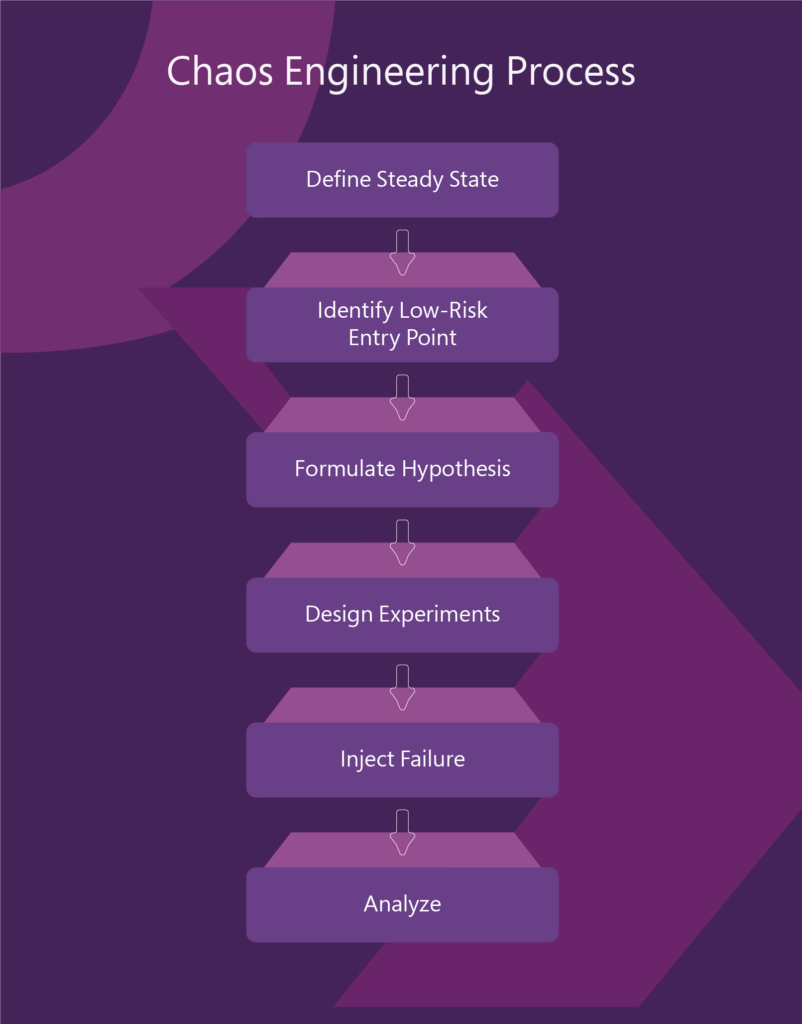
Imagine You’re the SRE Lead at a Fintech Company…You’re responsible for ensuring 99.99% availability of a mission-critical payments API. Your architecture is microservices-based, running on Kubernetes, with peak traffic during market hours. Your team proposes introducing chaos engineering to proactively test system resilience.
Here’s how you’d implement it safely and effectively:
1. Define Your Steady State
You determine your baseline metrics:
Average latency: <150ms
Error rate: <0.5%
Success rate on payment submissions: >99.5%
This becomes your control against which chaos results will be compared.
2. Identify a Low-Risk Entry Point
You choose a non-customer-facing service—say, the notification service—for your first chaos test. Even if it fails, it won’t affect transactions. Start in a staging environment, then gradually test in production with feature flags and circuit breakers.
3. Craft the Hypothesis
You hypothesize: “If one pod of the notification service is killed, Kubernetes should auto-restart it, and the system should remain healthy.” This gives your experiment a measurable goal.
4. Inject Failure with Guardrails
You use Chaos Engineering tool like Qinfinite to terminate a pod. You’ve already configured:
- Real-time dashboards tracking key metrics
- Alerts if error rates exceed 0.5%
- Abort conditions to stop the test if CPU spikes or pod recovery takes longer than 5 seconds
5. Analyze and Learn
The system auto-recovers—but your dashboards show a 4-second delay in email notifications. You document this as a resiliency bottleneck and plan a fix.
6. Scale Up with Caution
With confidence from your first test, you start:
- Expanding to core services
- Simulating network latency, CPU starvation, and region outages
- Adding chaos testing as a weekly drill to your release pipeline
From identifying safe entry points to automating chaos tests and integrating them into DevOps pipelines, teams need more than just tools—they need a strategic partner who understands resilience engineering as a service.
To successfully implement the above chaos engineering process, you need the right partner.
That’s where Quinnox’s intelligent application platform Qinfinite comes in.
How Qinfinite’s Chaos Engineering Drives Resilience, Agility, and Confidence
Qinfinite’s Chaos Engineering offers a critical safety net—ensuring systems not only withstand failure but recover from it swiftly and intelligently.
Recognized by Gartner in its “Market Guide for Chaos Engineering”, Qinfinite is more than a tool—it’s a strategic enabler for SRE and DevOps teams to proactively test, learn, and evolve.
Here’s a detailed look at the transformational benefits it brings to enterprise IT environments:
- Stronger System Resilience & Uptime: Identify and fix vulnerabilities early—boosting resilience by 20–30% and cutting production downtime by up to 25%.
- Fewer Outages & Faster Recovery: Reduce incident frequency by 15–25% and slash Mean Time to Recovery (MTTR) by 25–40% through tested failover strategies.
- Improved Customer Experience: Achieve a 10–20% jump in customer satisfaction with fewer disruptions and more consistent performance.
- Smarter Resource Utilization: Cut firefighting efforts by 15–20%, allowing teams to focus on innovation instead of incident management.
- Greater Team Collaboration & Change Confidence: Improve cross-functional coordination by 10–15% and boost deployment confidence by 20–30% via safe, failure-ready environments.
At Qinfinite, we believe that resilience isn't just about reacting to failures—it's about preparing for them. Chaos Engineering helps organizations turn the unknown into a competitive advantage by proactively identifying weaknesses before they impact customers. Our platform empowers DevOps and SRE teams to ensure systems are not just operational, but truly resilient, fostering trust, improving uptime, and driving continuous innovation.
- Arun CR, Head of Engineering & SVP, Qinfinite
Closing Line:
Chaos Engineering is a must-have practice to maintain customer trust, business continuity, and operational excellence. Organizations that embrace failure proactively through Chaos Engineering don’t just survive—they thrive. And with a strategic partner like Qinfinite, you gain the intelligence, tooling, and automation needed to build truly resilient digital experiences.
Ready to future-proof your infrastructure? Explore Qinfinite’s Chaos Engineering capabilities today and discover how your team can turn unknown failures into known strengths.
Data migration projects are critical for digital transformation but come with common challenges that can derail progress. Here’s a look at four major pitfalls—and how to avoid them:
With iAM, every application becomes a node within a larger, interconnected system. The “intelligent” part isn’t merely about using AI to automate processes but about leveraging data insights to understand, predict, and improve the entire ecosystem’s functionality.
Consider the practical applications:
In the Infinite Game of application management, you can’t rely on tools designed for finite goals. You need a platform that understands the ongoing nature of application management and compounds value over time. Qinfinite is that platform that has helped businesses achieve some great success numbers as listed below:
1. Auto Discovery and Topology Mapping:
Qinfinite’s Auto Discovery continuously scans and maps your entire enterprise IT landscape, building a real-time topology of systems, applications, and their dependencies across business and IT domains. This rich understanding of the environment is captured in a Knowledge Graph, which serves as the foundation for making sense of observability data by providing vital context about upstream and downstream impacts.
2. Deep Data Analysis for Actionable Insights:
Qinfinite’s Deep Data Analysis goes beyond simply aggregating observability data. Using sophisticated AI/ML algorithms, it analyzes metrics, logs, traces, and events to detect patterns, anomalies, and correlations. By correlating this telemetry data with the Knowledge Graph, Qinfinite provides actionable insights into how incidents affect not only individual systems but also business outcomes. For example, it can pinpoint how an issue in one microservice may ripple through to other systems or impact critical business services.
3. Intelligent Incident Management: Turning Insights into Actions:
Qinfinite’s Intelligent Incident Management takes observability a step further by converting these actionable insights into automated actions. Once Deep Data Analysis surfaces insights and potential root causes, the platform offers AI-driven recommendations for remediation. But it doesn’t stop there, Qinfinite can automate the entire remediation process. From restarting services to adjusting resource allocations or reconfiguring infrastructure, the platform acts on insights autonomously, reducing the need for manual intervention and significantly speeding up recovery times.
By automating routine incident responses, Qinfinite not only shortens Mean Time to Resolution (MTTR) but also frees up IT teams to focus on strategic tasks, moving from reactive firefighting to proactive system optimization.
FAQ’s Related to Chaos Engineering
It helps DevOps teams proactively test system failures, build confidence in deployments, and reduce downtime through improved resilience.
It aligns with SRE goals by validating system reliability, uncovering hidden faults, and improving incident response and recovery processes.
Examples include shutting down services, simulating latency, network failures, CPU/memory spikes, or dependency outages to observe system behavior.
Yes, but risks are minimized by defining a small blast radius, using observability tools, and running experiments during low-traffic periods with rollback plans in place.