Enterprises today generate and collect more data than at any point in history. According to Statista, global data storage is projected to exceed 200 zettabytes by 2025 and will triple between 2025 and 2029, driven by cloud adoption, digital platforms, IoT, and AI-powered applications. Yet despite this data explosion, most organizations still struggle to convert that data into a competitive advantage.
The challenge is not storage, compute, or even analytics capability. Cloud platforms have commoditized those capabilities. The real constraint lies elsewhere – inability to bring data together across products, platforms, clouds, and business units in a way that is trusted, governed, scalable, and ready for decision making.
This is where Big Data Integration becomes mission-critical, and it is the connective tissue that transforms raw, disconnected data into a reliable enterprise asset-ready for decision-making, automation, and AI.
For CIOs, CDOs, and technology leaders, the stakes are high. Gartner estimates that poor data quality costs organizations an average of $12.9 million per year, while McKinsey reports that data-driven organizations are 23 times more likely to acquire customers and 6 times more likely to retain them. Without an integrated data foundation, these outcomes remain aspirational.
In this blog, we talk about Big Data Integration from a leadership lens. It covers what it is, how the integration process works, where most enterprises struggle, the strategic and financial benefits, the proven best practices, and real examples of organizations that have done it right.
What is Big Data Integration?
Big Data Integration is the discipline of collecting, consolidating, transforming, governing, and distributing very large and diverse datasets across systems so that they can be used for analytics, automation, artificial intelligence, compliance, and digital experiences at enterprise scale.
In practical enterprise terms, Big Data Integration enables the following:
- Bring together structured, semi-structured and unstructured data from internal and external systems
- Standardize, enrich, and model data into business-friendly, analytics-ready formats
- Apply governance controls for lineage, quality, security, and access
- Deliver the data to warehouses, lakes, lakehouses, operational systems, and applications in the required frequency, including batch, micro batch, and real-time streaming
- Ensure data is discoverable, trusted, and consumable by analysts, data scientists, business applications, and machine learning models
When executed well, Big Data Integration becomes the foundation for any modern data platform. It turns data into a reusable asset rather than a series of single use pipelines built in isolation.
The Big Data Integration Process Explained
While implementations vary, most successful. Big Data Integration programs follow a consistent lifecycle:
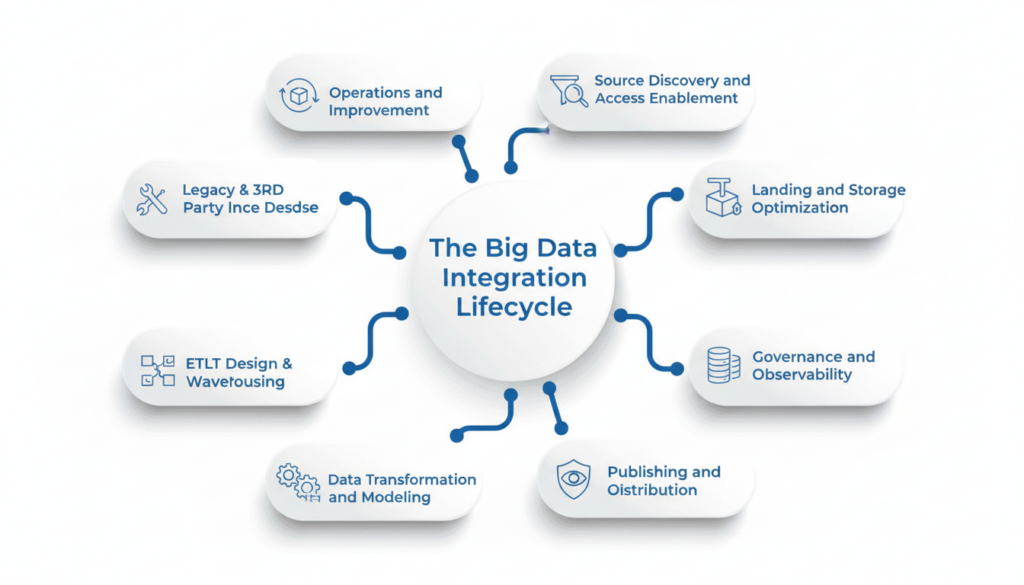
1. Source discovery and access enablement
Integration begins with visibility. Most enterprises operate across dozens, sometimes hundreds of systems spanning ERP, SaaS, legacy platforms, and external partners. A research shows that over 50% of enterprises integrate data from more than 50 sources, making structured discovery essential. High-performing teams formally catalog sources, assign ownership, define data contracts, and establish secure access across on-prem and cloud environments. This prevents blind spots and eliminates duplicate pipelines before they start.
2. Data ingestion design
Once sources are known, the key decision is how fast data really needs to move. Not all data requires real-time ingestion and forcing it often drives unnecessary cost.
Batch ingestion works well for historical and regulatory reporting. Change data capture keeps transactional systems current without heavy load. Streaming supports use cases like fraud detection or real-time personalization. Aligning ingestion patterns with business need – rather than technical preference – is what keeps integration scalable.
3. Landing and storage optimization
Where data lands and how it is stored has a direct impact on performance and cost. Poor partitioning or inefficient formats can increase analytics costs by 30–50%, even on modern cloud platforms. Leading organizations optimize storage based on consumption patterns, using columnar formats for analytics, intelligent partitioning, and retention policies that balance compliance with cost efficiency. Storage design becomes a financial decision, not just a technical one.
4. Data transformation and modelling
This is where data starts to speak the language of the business. Raw fields are standardized, entities are harmonized, and metrics are defined consistently. For AI initiatives, this step is critical. Gartner repeatedly cites poor data preparation as a major reason AI initiatives fail to scale. Well-modeled, feature-ready datasets make the difference between experimental models and production-grade intelligence.
5. Governance and observability
As usage grows, trust becomes fragile. Governance embedded into the integration lifecycle – quality checks, lineage tracking, and access controls – prevents confidence from eroding. This is not just about compliance. Gartner estimates that poor data quality costs organizations $12.9 million per year on average, largely due to rework and decision delays. Observability turns integration from a black box into a transparent, reliable system.
6. Publishing and distribution
Integrated data delivers value only when it is easy to consume. Certified datasets, semantic layers, APIs, and feature stores ensure analysts, applications, and AI models all work from the same source of truth. Retail and banking leaders often use this approach to power consistent dashboards, personalization engines, and operational workflows – without rebuilding logic for each use case.
7. Operations and continuous improvement
Integration does not end at go-live. Data volumes grow, costs drift, and priorities change. Mature organizations continuously monitor freshness, failures, usage, and cost – retiring low-value pipelines and optimizing high-impact ones. This is why the most successful enterprises treat Big Data Integration as a long-term capability, not a completed project.
For building a roadmap, it is useful to complement this lifecycle with a structured data integration strategy that aligns with business priorities and investment timelines.
Key Challenges in Big Data Integration
Even highly funded data initiatives fail when integration is treated as an afterthought. Below are the challenges most enterprises face.
| Challenge | Executive Impact |
|---|---|
| Data variety and schema drift | Rework and delays in analytics, unreliable insight |
| Latency mismatch across systems | Inability to support real time use cases or ML features |
| Data quality issues | Poor trust in dashboards and regulatory exposure |
| Privacy and security controls | Audit failure and customer data risk |
| Tool and platform fragmentation | High cost of ownership and skills shortage |
| Siloed ownership and unclear accountability | Slow issue resolution and duplication of work |
| Lack of lineage and observability | Root cause analysis takes days instead of minutes |
| Scaling cost without value tracking | Spend grows faster than business impact |
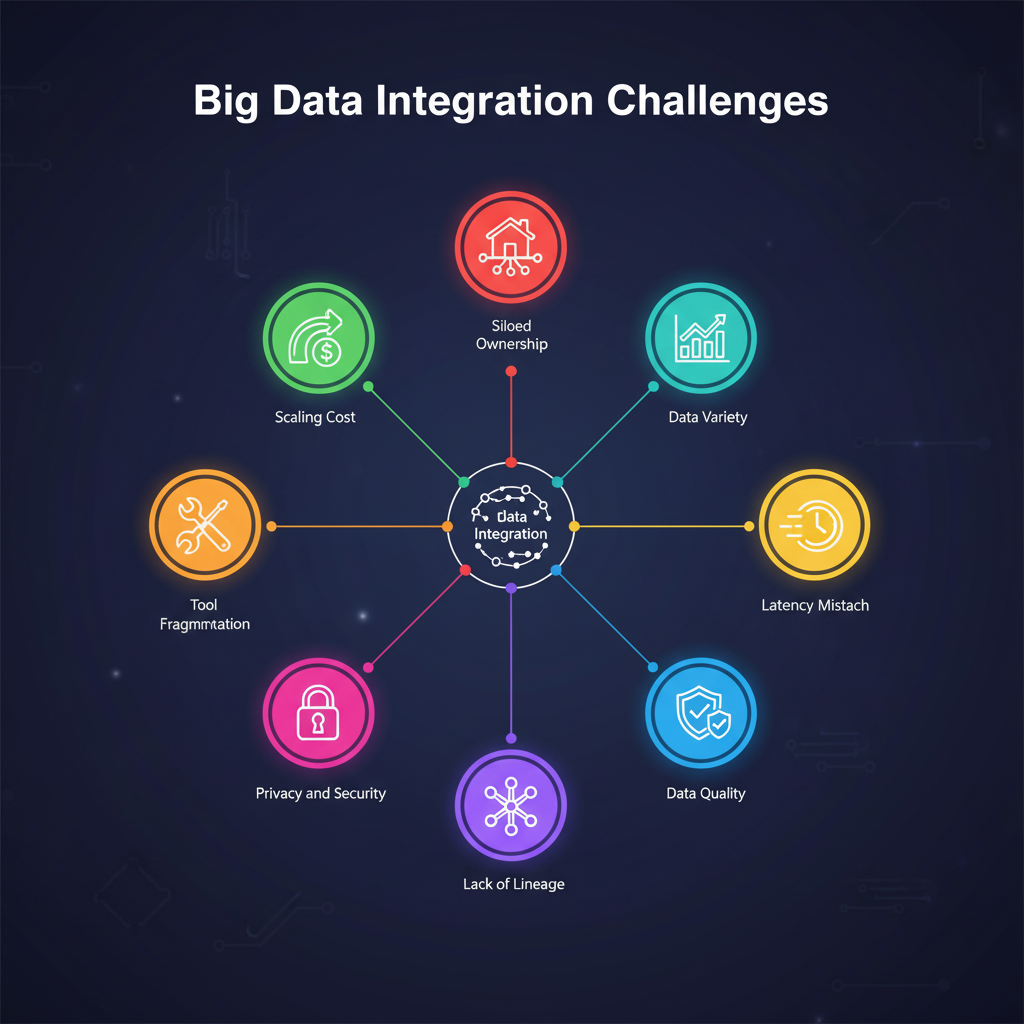
Many of these issues arise because integration is treated purely as an engineering exercise rather than a governed enterprise capability. A shift in mindset is required where integration is seen as a data supply chain that powers every business function.
For deeper approaches on resolving these issues, refer to enterprise data integration and data integration techniques.
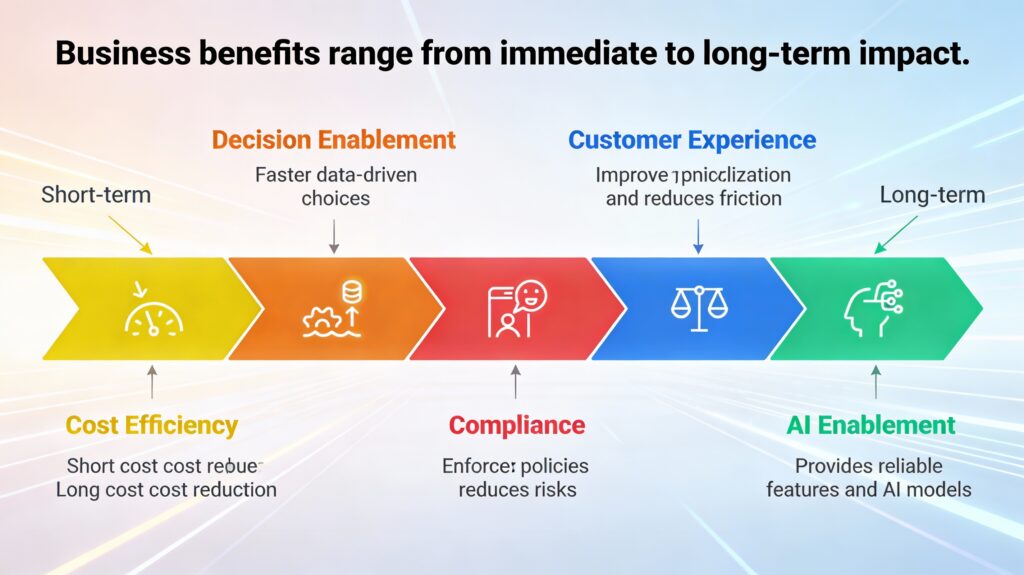
Business Benefits of Big Data Integration
When enterprises invest in Big Data Integration as a foundational capability, the benefits accrue progressively – starting with faster decisions and cost efficiency and extending to compliance resilience and AI enablement. The impact is both immediate and compounding.
1. Decision Acceleration
The first and most visible benefit of integrated data is speed. When data from finance, operations, customers, and partners is unified and trusted, reporting cycles shrink dramatically – from days or weeks to minutes or hours.
Business leaders gain near real-time visibility into performance, enabling faster forecasting, scenario analysis, and course correction. Instead of debating whose numbers are correct, teams focus on what action to take. This shift alone can materially improve responsiveness in sales, supply chain, and operations.
2. Cost Efficiency Through Reuse
As integration matures, cost benefits begin to surface. Reusable ingestion pipelines, standardized transformation logic, and shared governance reduce the need for teams to rebuild the same data flows repeatedly.
This lowers engineering effort, reduces cloud waste, and improves overall data platform efficiency. Organizations move away from fragmented, one-off integrations toward a common data supply chain – cutting both operational cost and technical debt while increasing delivery velocity.
3. Customer Experience Improvement
With integrated data, organizations can finally deliver consistent, personalized experiences across channels. Customer interactions, transactions, preferences, and service history come together into a single, reliable view.
This enables targeted personalization, proactive issue resolution, and smoother digital journeys for customers and similarly improves employee experience by reducing manual work and context switching. Friction decreases, satisfaction improves, and engagement becomes more meaningful rather than reactive.
4. Compliance and Risk Reduction
As data usage scales, governance becomes non-negotiable. Big Data Integration with built-in lineage, quality checks, and access controls simplifies compliance with regulatory requirements and internal policies.
Audits become faster and less disruptive because data flows are traceable end to end. Sensitive data is protected without blocking access for legitimate use. The result is lower regulatory risk, stronger controls, and greater confidence in how data is handled across the enterprise.
5. AI Enablement and Long-Term Competitive Advantage
The most strategic benefit of Big Data Integration emerges over time: AI readiness. Reliable, well-governed, and continuously refreshed data is the foundation for successful analytics and AI initiatives.
McKinsey reports that nearly 70% of AI initiatives fail to scale, most often due to data integration and quality issues. Organizations that solve integration first provide AI models with consistent, high-quality features – improving accuracy, trust, and time to value.
Over the long term, this enables predictive insights, intelligent automation, and scalable AI-driven decision-making – turning data into a sustained competitive advantage rather than isolated experiments.
The progression is clear: Big Data Integration delivers quick wins in decision speed, mid-term gains in cost and experience, and long-term value through compliance strength and AI enablement.
Organizations that treat integration as a long-term enterprise capability – rather than a one-time project – consistently see higher returns on data investments and are better positioned to compete in an increasingly data-driven economy.
Best Practices for Big Data Integration
The following practices are drawn from successful enterprise scale programs. They represent a maturity path rather than a checklist.
1. Start with business outcomes not data sources
Define the high value decisions you want to improve. Map those decisions to required data domains and service levels. Work backward from value not from system inventory.
2. Establish service tiers for latency and availability
Not all data needs to be real time. Define gold silver and bronze service levels and assign data products accordingly. This prevents overspending and simplifies operational expectations.
3. Use data contracts to control change
Document schemas ownership SLAs and quality rules as contracts between producers and consumers. Enforce compatibility and automate alerts on breaking changes.
4. Standardize ingestion patterns
Adopt repeatable ingestion frameworks for batch change, data capture and streaming. Use managed connectors where possible to reduce maintenance overhead.
5. Govern data quality and lineage from day one
Instrument quality rules for every critical dataset. Capture lineage automatically rather than through documentation. This is essential for both compliance and issue diagnosis.
6. Apply security and privacy as code
Use policy engines to enforce masking encryption tokenization and role based access. Avoid manual approvals and static ACLs that do not scale.
7. Optimize storage formats and file layout
Use columnar formats for analytics. Compact small files regularly. Partition data based on query patterns not based on source system assumptions.
8. Bring observability into the data platform
Track metrics like freshness, completeness, failure rate and cost per job. Provide dashboards to data product owners not just engineers.
9. Use AI selectively in integration workflows
Machine learning can accelerate mapping anomaly detection and metadata enrichment. GenAI can support documentation and data discovery. For deeper analysis see ai in data integration.
10. Treat data assets like products
Define owners SLAs roadmaps and user feedback loops. Product thinking drives reliability adoption and continuous enhancement.
Real World Examples of Big Data Integration
- Retail consumer analytics
A global retailer unified ecommerce transactions store sales clickstream events and loyalty data into a central lakehouse. Marketing gained a single view of the customer. Merchandising optimized stock by predicting demand at store level. Personalization use cases increased conversion and reduced churn.
- Banking fraud and compliance
A payments company integrated device telemetry transaction history blacklists and third party risk feeds. A feature store powered real time fraud scoring. Losses dropped and regulatory audits became faster thanks to end to end lineage.
- Healthcare patient engagement
A healthcare network combined EHR data claims records and wearable streaming signals. Predictive models identified high risk patients and enabled clinicians to intervene earlier. Privacy controls tokenized sensitive fields without limiting research access.
- Manufacturing and predictive maintenance
A manufacturer streamed sensor data from equipment across multiple plants. Aggregated readings fed models that predicted failure before it happened. Planned downtime replaced unplanned disruption and spare part inventory was optimized.
- Logistics and route intelligence
A logistics firm integrated telematics weather feeds fuel usage and order data. Dynamic routing reduced fuel cost and improved arrival accuracy. Customers received live status updates through integrated APIs.
These examples show that the value of Big Data Integration is not data centralization. It is decision enablement.
Conclusion
Big Data Integration determines whether an enterprise becomes data driven in practice or remains data rich but insight poor. It is the gateway to trusted analytics, scalable AI, regulatory compliance, and operational efficiency. The organizations that succeed treat integration as a strategic capability, invest in governance and automation, and align data products with business outcomes.
The real question for leaders now is this: Is your data integration foundation strong enough to support the AI, regulatory, and growth ambitions on your roadmap?
This is where Quinnox helps enterprises move faster with confidence. By combining deep integration expertise, AI-driven automation, and governance-first frameworks, Quinnox enables organizations to modernize their data supply chains without adding complexity or risk. The focus is not just on moving data but on delivering measurable business impact from it.
If you are shaping your next data integration roadmap, now is the moment to move from fragmented efforts to an integrated, intelligent foundation.
FAQs about Big Data Integration
To unify data from many sources into trusted, governed, and consumable datasets that support analytics, machine learning, and operational use cases at enterprise scale.
It enables streaming ingestion, low latency transformations, and serving layers optimized for prompt access. With change data capture and event backbones, new data becomes queryable quickly, which powers alerting, personalization, and time sensitive decisions.
Skipping data contracts and schema governance, treating all datasets as if they require the same latency, ignoring quality tests until users complain, granting broad access without masking and audit, and failing to invest in observability. Another frequent mistake is adopting many tools without a clear operating model, which raises cost and complexity.
Cloud provides elasticity, a rich ecosystem of managed services, and global reach. It simplifies experimentation and scale up. The best approach depends on regulatory needs, data gravity, and skills. Many enterprises adopt a hybrid model that uses cloud for flexible processing and storage while keeping sensitive workloads and data sets in controlled environments. The key is a strategy that places each workload where it runs most effectively, supported by governance that travels with the data.