Consider a scenario where your organization runs multiple interconnected digital services – payment systems, customer apps, backend platforms, and data pipelines – all exchanging millions of signals every day. One small slowdown in a database, API, or cloud function can ripple across the system, triggering outages that customers feel almost instantly.
This is the new normal.
Enterprises today face unprecedented operational complexity: distributed cloud environments, microservices, third-party integrations, and real-time experience expectations. Meanwhile, the average cost of downtime has surged to $5,600 per minute, with high-transaction sectors facing losses of over $1M (Gartner). And the data that teams rely on to prevent incidents isn’t helping – observability data volumes are increasing 25–30% every year, overwhelming even the most experienced SRE and Ops teams (Splunk, 2024).
Traditional incident response models were built for simpler environments – and they are cracking under scale. This is where AI is shifting the paradigm. AI is now central to modern incident management – correlating signals at machine speed, predicting failures before they impact users, reducing MTTR, and automating safe remediation. Organizations adopting AI-driven incident operations report up to 60% faster resolution and 30–50% fewer customer-visible outages.
The result is simple: AI isn’t just optimizing incident management – it’s redefining it. This blog explores what’s changing, why it matters, where AI delivers impact, and how organizations can adopt it effectively.
The Starting Point: What Incident Management Looked Like Pre-2025
Traditional incident management was largely reactive. Tools ingested alerts from monitoring stacks, tickets were created, people triaged, and resolution paths were followed from runbooks. The problems were predictable: alert storms, noisy signals, manual triage, long mean time to repair (MTTR), and poor cross-team context.
But the landscape changed rapidly: cloud-native architectures, microservices, distributed tracing, and skyrocketing observability data made manual approaches impractical. Many organizations responded by layering automation and analytics, which set the stage for AI-driven incident operations. PagerDuty’s survey, for example, reported a 16% year-over-year increase in enterprise incidents as companies raced to adopt AI and cloud services – evidence that scale, not human will, drove change.
Traditional Challenges in Incident Management
Before we explore how AI is reshaping incident response, it’s important to recognize why traditional methods are no longer sufficient. Modern systems are far more distributed, dynamic, and interdependent than the monolithic environments where incident management processes were originally built. As digital complexity scales, the cracks in legacy processes become impossible to ignore.
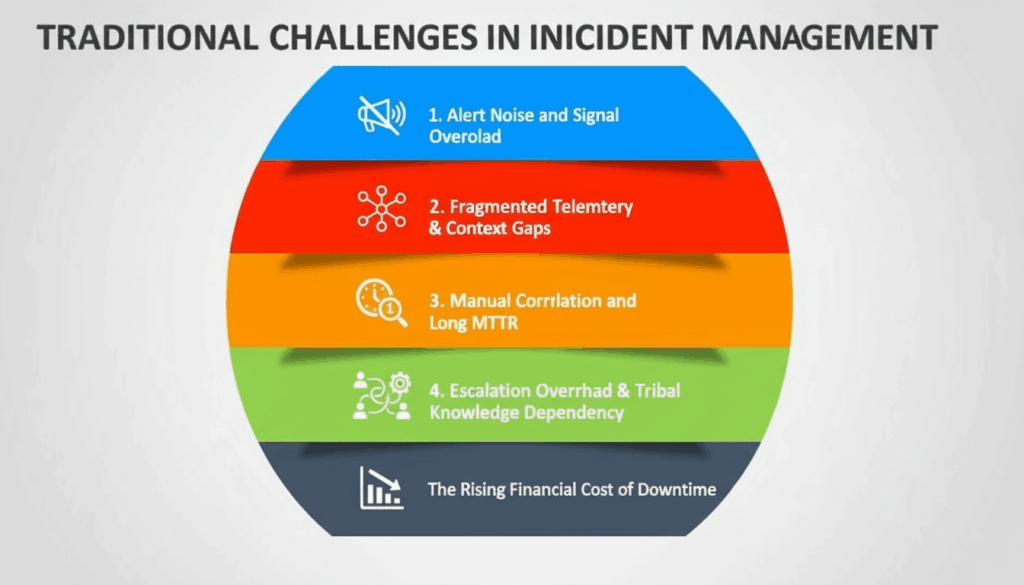
1. Alert Noise and Signal Overload
Modern cloud-native environments generate massive volumes of telemetry data across logs, metrics, traces, health checks, and audit events. A typical enterprise monitoring stack can produce tens of thousands of alerts per day – many of which are duplicates, informational, or triggered by cascading dependencies rather than root causes.
- 68% of Ops teams struggle with alert fatigue, leading to genuine incidents being missed (Source: PagerDuty State of Ops, 2023).
- One Fortune 500 ecommerce platform reported receiving over 120,000 alerts during a single holiday sale weekend, with only 0.3% requiring human intervention.
What this causes? Engineers become desensitized to alarms, slow to respond, or forced into reactive firefighting instead of proactive prevention.
2. Fragmented Telemetry & Context Gaps
Historically, monitoring tools evolved in isolation:
| Data Type | Common Tools | Problem |
|---|---|---|
| Metrics | Prometheus, Datadog | Shows impact, not root cause |
| Logs | Splunk, ELK Stack | Hard to correlate with metrics |
| Traces | Jaeger, OpenTelemetry | Often incomplete across services |
| Config & Change Data | Git, CI/CD tools | Rarely linked to observability data |
Without contextual correlation, teams are forced to jump between dashboards, manually guess relationships, and correlate symptoms with possible sources.
- 45% of MTTR time is spent just gathering and reconciling data across tools
- Enterprises today manage 20–45+ individual monitoring tools on average.
3. Manual Correlation and Long MTTR
In many organizations, resolving incidents still depends heavily on human intuition, tribal knowledge, and pattern recognition. Root cause analysis requires engineers to stitch together signals manually:
- Logs from one service
- Metrics from another
- Traces from a third
- Deployment history from a fourth
This results in high Mean Time to Detect (MTTD) and Mean Time to Repair (MTTR).
- The average MTTR across industries is 4.9 hours.
- During critical incidents, up to 65% of resolution time is spent diagnosing the root cause, not fixing it.
For Example, a microservice fails intermittently due to a misconfigured circuit breaker threshold. Engineers spend hours chasing timeout logs across multiple components before realizing the configuration pushed during a previous deployment triggered cascading failures.
4. Escalation Overhead & Tribal Knowledge Dependency
Many incident playbooks are documented poorly or live in the minds of the most experienced engineers. When a major outage occurs, teams scramble to:
- Assemble war rooms
- Assign responsibilities manually
- Contact senior engineers who know “how things really work”
This creates bottlenecks and single points of knowledge failure.
- 73% of organizations admit their incident response depends on a few key individuals (Source: SC Media). When these individuals are unavailable, MTTR increases by 40 – 70%.
5. The Financial Cost of Downtime Is Rising
The stakes of outages are no longer just operational – they are strategic and reputational.
- Earlier industry estimates placed downtime around $5,600 per minute (Gartner).
- Recent operational risk research shows enterprise downtime has now risen to $14,000–$18,000 per minute on average (Source: Forbes).
- For digital-first businesses (fintech, streaming, ecommerce), major outages can exceed $1M+ per hour.
Every minute of MTTR now correlates directly with revenue loss, churn probability, SLA penalties, and brand damage.
The AI Building Blocks Now Powering Modern Incident Management
Modern incident management is no longer just about monitoring dashboards and responding when something breaks. Today’s systems are too distributed, too dynamic, and too fast-moving for manual troubleshooting alone. Instead, incident response is increasingly powered by a layered set of AI-driven capabilities working together to detect issues earlier, interpret system signals faster, and automate resolution steps when risk is low.
Let’s break this down into five core building blocks shaping how teams detect, diagnose, and resolve issues today.
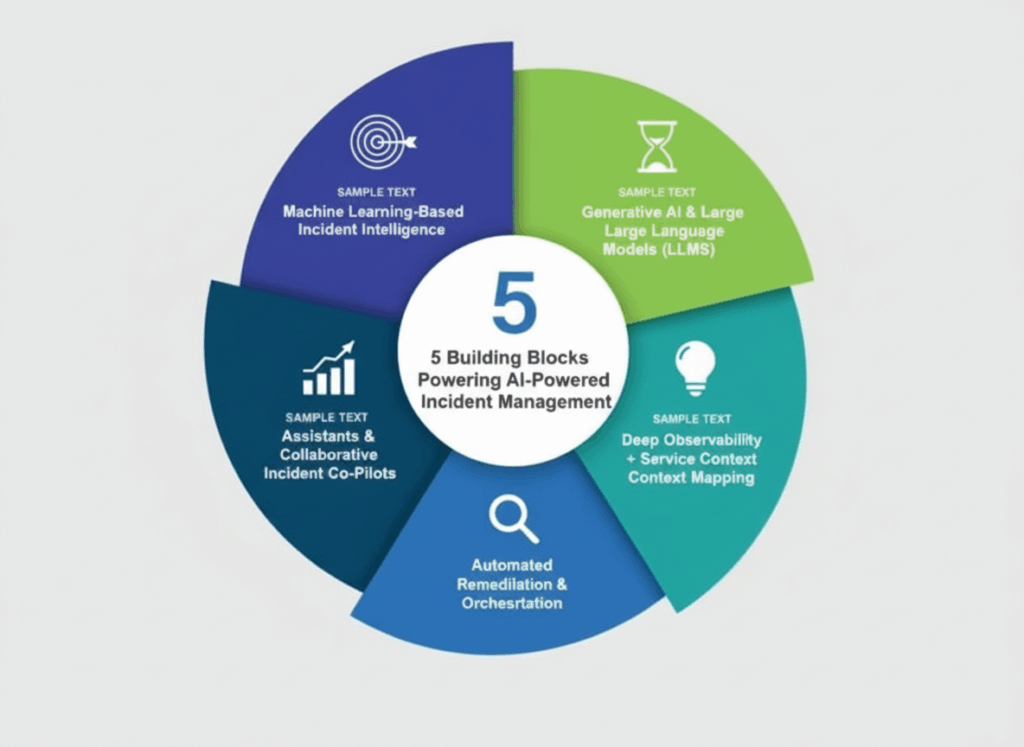
1. Machine Learning-Based Incident Intelligence
At the heart of AI-driven incident management is machine learning that analyzes operational signals at scale. This includes logs, metrics, traces, events, change records, performance thresholds, and more.
Instead of engineers manually sorting through thousands of alerts, ML models can:
- Spot unusual behavior (anomaly detection) – e.g., CPU spikes that deviate from historical baselines.
- Group related alerts into meaningful incident clusters.
- Identify patterns that repeat past outages.
- Suggest probable root causes (e.g., “90% correlation with past failures caused by a deployment misconfiguration in Service A”).
This does what humans cannot do fast enough: separate signal from noise.
2. Generative AI & Large Language Models (LLMs)
Generative AI acts as the “explanation layer” on top of operational data. It enables engineers to:
- Ask system questions in plain English. For Example: “What changed in the payments service before error rates spiked?”
- Get real-time incident summaries (instead of reading through dashboards).
- Generate postmortems and report documentation automatically.
- Recommend potential remediation steps based on past incident history and runbooks.
This reduces the reliance on tribal knowledge, speeding up resolution even for junior engineers.
Example Usage
- During an outage, an engineer types:
“Why is API latency high for checkout?”
- The assistant returns: “Latency increased after yesterday’s config push to Service Checkout v2.4. Restarting the pod typically resolves similar incidents. See incident #2023-178 and #2024-032.”
Did You Know? By 2025, 80% of IT operations platforms will include embedded GenAI assistants
3. Deep Observability + Service Context Mapping
Observability tools now collect far more than raw telemetry from services — they map the relationships between services, users, and infrastructure layers. This contextual visibility allows teams to answer crucial questions like:
- Which downstream services break if Service X fails?
- Which business customer workflows are impacted right now?
This unlocks:
- Faster triage (no guessing which team to call).
- Prioritization based on user impact (not just infrastructure metrics).
- More accurate root-cause linkage to recent deployments or configuration changes.
According to industry research, organizations with contextual observability see up to 3× faster incident triage.
4. Automated Remediation & Orchestration
AI doesn’t just detect issues – it can now fix them in many environments. When the system is confident about the root cause, it can trigger pre-verified remediation steps:
- Restart a degraded service.
- Roll back a problematic deployment.
- Scale infrastructure automatically.
- Flush corrupted caches.
- Apply configuration updates to route traffic around faulty nodes.
This reduces MTTR dramatically, especially recurring/known incident patterns. Organizations implementing automated remediation report 40–60% reduction in MTTR (Source: PagerDuty Automation Benchmark).
5. Conversational Assistants & Collaborative Incident Co-Pilots
Finally, the interaction model is changing. Instead of complex dashboards, engineers troubleshoot through chat-like assistants integrated into: Slack / Teams war rooms, incident response playbooks and service management consoles. These assistants act as co-pilots, offering:
- Real-time summaries
- Suggested next actions
- Impact assessment across teams
- Clear “who owns what” escalation steps
This helps teams collaborate faster, make fewer missteps, and avoid duplicated effort during high-pressure incidents.
Why These Building Blocks Matter Together
Each component alone provides value – but together, they create a self-improving incident management engine:
| Layer | What it does | Impact on MTTR |
|---|---|---|
| ML Incident Intelligence | Detect patterns & reduce noise | ↓ MTTD |
| LLMs & GenAI | Explain, summarize, and guide | ↓ Cognitive load |
| Observability w/ Context | Map dependencies & blast radius | ↓ Triage time |
| Automated Remediation | Execute safe fixes | ↓ Time to resolution |
| Conversational Assistants | Human-machine collaboration | ↓ Escalation cycles |
The result:
- Faster problem detection
- More accurate diagnosis
- Reduced reliance on senior-only expertise
- Fewer outages and failed deploys
- Lower operational cost
Key Transformations - What changes for real in incident operations
Below are the big shifts organizations actually experience when AI is applied sensibly.
1. Predictive Detection: Catching Incidents Before They Become Incidents
AI models trained on historical telemetry and business context begin to surface incidents-in-the-making – slow degradations, anomalous error patterns, and precursors to cascading failures. Predictive detection turns many incidents into scheduled maintenance or automated remediation opportunities rather than emergency page-storms.
Why it matters: Proactive fixes reduce customer impact and cost of downtime.
According to Research Square study, AIOps engines can detect precursors and reduce full-blown incidents; academic and industry research finds notable improvements in detection rates and MTTR reductions when predictive ML is deployed.
2. Automated Triage and Intelligent Routing
AI clusters related alerts into coherent incidents, maps them to likely owners, and prioritizes based on business impact (e.g., payment service vs. internal analytics). That means the right person is paged with the right context, reducing cognitive load and wasted handoffs.
3. Root Cause Analysis (RCA) at Machine Speed
Instead of a page with a stack trace and a link, responders receive a prioritized list of probable causes with supporting evidence (timestamps, correlated traces, recent deployments). Vendors demonstrate significant triage speedups in customer case studies – e.g., a major payments customer reported 50% faster triage after adopting observability AI.
4. Automated Remediation and Safe Runbooks
Pre-approved runbooks can be executed automatically once AI reaches a confidence threshold (for example, restart a failing worker pool when error rates exceed a modeled boundary). Early adopters run safe, gated automations and progressively widen automation coverage as trust grows.
5. Conversational Assistants & LLM-enabled Insights
Large language models (LLMs) let engineers query telemetry in plain English (“show me errors for checkout service in Mumbai in last 30 minutes”) and receive synthesized answers, charts, or remediation suggestions – lowering the barrier for junior responders and speeding expert workflows.
Measurable benefits of AI in Incident Management
You can argue AI’s promise endlessly, but businesses care about numbers. Here are the measurable outcomes backed by vendor reports and studies:
- MTTR reductions: Several industry reports and studies (including recent AIOps research) show MTTR improvements ranging from 25–40% or more when AIOps and automated response are applied. Some customer case studies report even larger gains for specific workflows.
- Reduced alert fatigue and better focus: AI can eliminate up to 90% of noisy or duplicate alerts in some environments, giving engineers back the ability to focus on high-value actions rather than triage noise.
- Cost avoidance and revenue protection: Given the rising cost of downtime (see earlier), even small MTTR improvements can translate to large dollar savings. Firms running automated remediation and predictive detection protect revenue and reduce reputational risk. Recent surveys show organizations increasing their operations budgets for AI and automation – underlining the perceived ROI.
- Incident frequency insight: PagerDuty’s study highlighted a 16% increase in incidents tied to complex modern stacks – a signal that scaling manual processes is unsustainable, and that automation investments are required.
- Market momentum: Market analysts estimate the AIOps market is growing quickly – depending on the source, forecasts for 2025 market size vary (examples: reported 2024 valuations around single-digit to mid-double-digit billions and projected strong CAGR into the 2030s). This reflects rapid vendor investment and enterprise uptake.
Takeaway: real customers are seeing real improvements in both time and cost metrics. The exact numbers depend on maturity and workloads, but the direction is clear.
Challenges of AI in Incident Management
AI is powerful but not without hazards. Here are the common challenges and pragmatic mitigations.
1. False positives & over-automation
If models are poorly tuned, automation can act incorrectly (e.g., scaling down a recovering service). Mitigation: Start with “assistive” modes, require human approval for risky actions, and enforce conservative confidence thresholds.
2. Data quality and context gaps
AI models need consistent, high-fidelity telemetry and topology data. Garbage in → garbage out. Mitigation: Invest in observability of hygiene (consistent logs, service maps, enriched metadata) before automation.
3. Trust and explainability
Engineers need to understand why an AI recommended an action. Black-box automation breeds resistance.
Mitigation: Attach evidence of trails, confidence scores, and provenance for all AI suggestions.
4. Skill and process change management
Adopting AI changes roles: ops become oversight-focused. Without proper change management, teams can reject tools or misuse automation.
Mitigation: Run pilots, train staff, and evolve on-call policies to reflect the new human-AI boundary.
5. Privacy and compliance
Incident data can include PII or sensitive system information. Training or sharing telemetry carelessly risks leaks.
Mitigation: anonymize data, use private model deployments when needed, and document data retention and governance.
Practical Blueprint: How To Adopt AI For Incident Management
Below is a pragmatic roadmap for teams ready to move beyond pilots.
Step 1 – Instrumentation & observability hygiene
Before AI helps, you must have reliable telemetry: consistent logs, traces, metrics, and service topology. Prioritize high-impact services and business-critical paths.
Step 2 – Baseline metrics and KPIs
Measure current MTTR, MTTD, triage times, and incident frequency. This provides the A/B baseline to prove value later.
Step 3 – Start with augmentation, not autonomy
Deploy AI to assist with triage and RCA – seed recommendations, summaries, and suggested runbook steps. Keep manual approvals for actions initially.
Step 4 – Iterate with human feedback loops
Capture when humans accept/reject AI suggestions; feed that data back into model tuning to increase precision and trust.
Step 5 – Safe automation gating
Define confidence thresholds, rollback paths, and circuit breakers. Start with low-risk automations (e.g., log collection, alert enrichment) then progress to automated remediation.
Step 6 – Post-incident intelligence & continuous improvement
Use AI to auto-generate postmortem drafts, extract root-cause patterns, and update runbooks. Track improvements in the KPIs defined in Step 2.
Step 7 – Governance & ethics
Document model data sources, retention, explainability, and audit trails. Ensure compliance and prepare for regulatory queries.
Check out on this read: Why Enterprises Must Prioritize Strict Governance for Ethical and Responsible Use of AI
The Future Beyond 2025 - Five Predictions
- Autonomous incident agents that can act across systems (with guardrails): Multi-agent systems will coordinate across observability, CI/CD, and cloud controls to autonomously resolve well-understood incidents.
- Edge & on-device AI for low-latency remediation: Critical infrastructures will run local models to handle faults when cloud connectivity is impaired (important for telco, healthcare, and utilities).
- Shift to outcome-based SLOs fed by AI: AI will continuously map incidents to business outcomes and optimize SLOs dynamically based on predicted risk and customer impact.
- Explainable, certified remediation playbooks for regulated industries: Compliance will drive certified AI runbooks where actions and evidence are auditable.
- Platform-native large models and observability synthesis: Observability vendors will ship models trained on anonymized, multi-tenant telemetry to offer synthesis and diagnostics as a native feature (this is already visible in 2024–2025 product launches).
The Bottom Line:
Moving from Reactive Ops to Intelligent, Autonomous Incident Management
The realities of today’s digital environments are clear: systems are more distributed, dependencies are more dynamic, and the stakes for downtime are higher than ever. Traditional incident management practices – rooted in manual correlation, tribal knowledge, and reactive firefighting – simply can’t keep pace. AI isn’t just a new layer of tooling; it’s an operational shift that transforms how teams detect, understand, and resolve incidents.
By bringing together real-time telemetry, context-driven analytics, autonomous remediation capabilities, and adaptive learning loops, AI-powered Incident Management pushes organizations beyond visibility into actionable intelligence and self-driving operations.
This is exactly where our intelligent application management platform, Qinfinite delivers value. Qinfinite unifies observability, event correlation, knowledge graphs, and AI-driven reasoning into a single Intelligent ServiceOps platform. Instead of adding “another tool” to an already cluttered stack, it acts as the brain that connects your systems, applies contextual logic, and orchestrates resolutions – automatically where possible, and with guided intelligence when human decisions are required
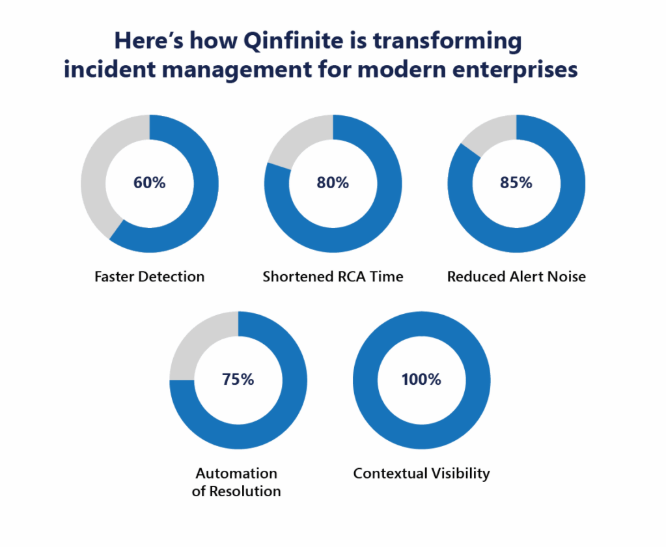
In other words, Qinfinite helps organizations evolve from “knowing something is wrong” to “understanding why-and fixing it fast.”
So, ready to move toward intelligent, self-healing operations? Book your free 120-mins consultation with Qinfinite experts to see how we can help transform your incident management strategy.
FAQ’s Related to AI in Incident Management
AI-based incident management uses machine learning, automation, and advanced analytics to detect, correlate, and resolve IT incidents faster. It reduces alert noise, identifies root causes, and can trigger automated remediation actions.
AI accelerates response by automatically grouping related alerts, analyzing telemetry in real time, and suggesting or executing the best remediation steps. This reduces manual analysis and significantly lowers Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR).
Yes. AI can analyze trends, anomalies, and past incident patterns to forecast potential failures. Predictive models allow teams to fix issues proactively – before they impact users.
No. AI augments human teams, not replaces them. It handles repetitive triage and correlation tasks so engineers can focus on strategic decisions, prevention, and system improvement.