Accelerate IT operations with AI-driven Automation
Automation in IT operations enable agility, resilience, and operational excellence, paving the way for organizations to adapt swiftly to changing environments, deliver superior services, and achieve sustainable success in today's dynamic digital landscape.
Driving Innovation with Next-gen Application Management
Next-generation application management fueled by AIOps is revolutionizing how organizations monitor performance, modernize applications, and manage the entire application lifecycle.
AI-powered Analytics: Transforming Data into Actionable Insights
AIOps and analytics foster a culture of continuous improvement by providing organizations with actionable intelligence to optimize workflows, enhance service quality, and align IT operations with business goals.
From decades-old policy administration systems and fragmented claims databases to disconnected underwriting platforms, insurers today are dealing with massive volumes of sensitive, business-critical data spread across outdated infrastructures. The challenge is not simply moving data from one system to another. It is about preserving accuracy, ensuring regulatory compliance, maintaining operational continuity, and protecting customer trust at every stage of the migration journey.
Unfortunately, many migration projects fail to meet expectations. Incomplete records, inconsistent data formats, prolonged downtime, integration failures, security vulnerabilities, and unexpected cost overruns can quickly turn a modernization initiative into a costly operational risk. Even a small migration error can lead to delayed claims processing, policy inaccuracies, compliance penalties, and damaged customer relationships.
According to BCG’s analysis, 35% of insurance applications still operate on legacy systems that are not cloud-ready. Meanwhile, technical debt compounds at nearly 20% annually — meaning a system carrying $1 million in technical debt today could double that burden within four years (PwC, 2026).
That is why successful insurers are moving beyond ad-hoc migration strategies and adopting structured, phased approaches designed to reduce risk and improve long-term outcomes.
This free 10-phase checklist is built specifically for insurance IT leaders, digital transformation teams, and operations executives who want to execute data migration projects with confidence. It provides a practical framework to help insurers identify risks early, improve data quality, streamline system transitions, and ensure business continuity throughout the migration lifecycle.
Whether you are replacing a legacy core platform, consolidating multiple systems after an acquisition, or preparing your organization for cloud modernization and AI-driven operations, this checklist will help you avoid common pitfalls and build a migration strategy that is secure, scalable, and future-ready.
Why Insurance Data Migrations Fail: The 5 Costliest Mistakes
“Insurance data migration isn’t a technology project. It’s a business transformation project that IT happens to be executed. The moment a leadership team understands that distinction, the project’s probability of success increases dramatically.” – Rachana Manjunath, Senior Architect – AI & Data, Everforth Quinnox
Understanding why data migrations fail is worth more than any technical guide. These five patterns account for the majority of project failures – and every one of them is preventable.
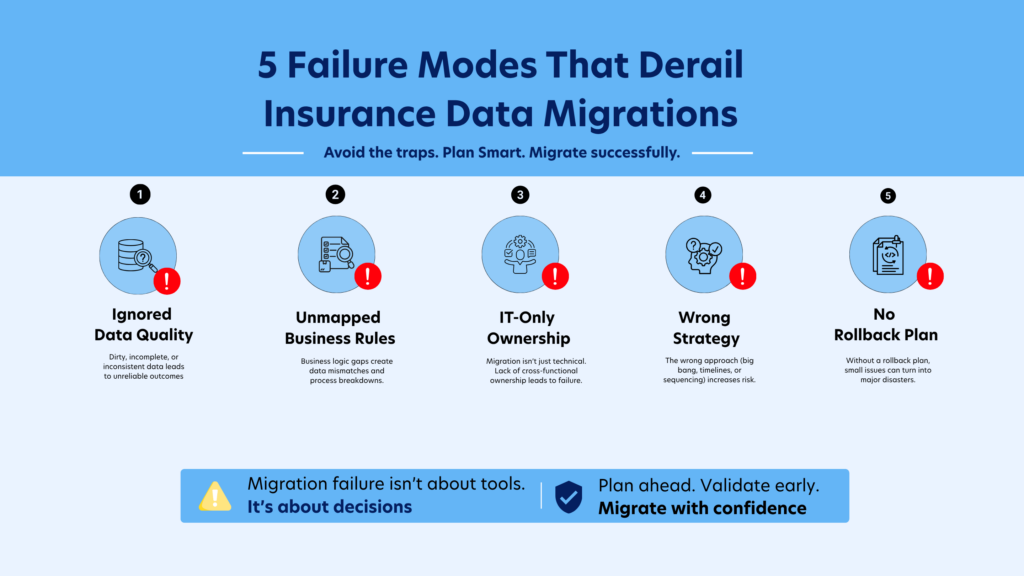
1. Deferred Data Quality Assessment
Data profiling is often underestimated. Legacy systems rarely contain “clean” data – duplicates, deprecated codes, placeholder values, and missing fields are common. When these issues surface late, they trigger rework cycles that delay timelines and inflate costs. Teams that invest early in profiling and cleansing avoid most downstream disruptions.
2. Incomplete Business Rule Documentation
Insurance systems embed critical business logic – pricing rules, claims calculations, endorsement flows – that isn’t always documented. Migrating data without capturing this logic results in data that is technically correct but operationally unusable. This requires close collaboration between IT and business teams during mapping.
3. Lack of Cross-Functional Governance
Migrations run purely by IT tend to fail at the business level. Without active involvement from underwriting, claims, and finance teams, validation gaps emerge late – often during UAT – leading delays and rework.
4. Misaligned Migration Strategy
Choosing between Big Bang and phased migration requires objective evaluation of data volume, dependencies, and downtime tolerance. Big Bang approaches often underestimate risk, while phased strategies distribute risk and allow iterative learning.
5. Untested Rollback Plans
Documentation is not preparation. Teams that have written a rollback procedure but never rehearsed it discover – during a production cutover failure at 2 am – that their procedure doesn’t actually work in the system state they’re in. Teams that have rehearsed rollback execute it with clarity and confidence. Pre-agreeing the rollback trigger criteria (if X fails by Y time, we roll back – no debate, no escalation) is as important as the procedure itself.
Understand the full landscape of data migration challenges.
From legacy system incompatibility to mid-migration data quality failures – a structured breakdown of the challenges and how leading teams address them.
A Structured Approach: The 10-Phase Insurance Data Migration Framework
Successful insurance data migration follows a structured, phase-driven methodology. The ten-phase framework below reflects best practice across insurance migration programs. Each phase has defined inputs, outputs, and quality gates that must be satisfied before the project proceeds.
Phase 1: Planning and Scoping
Define migration strategy (Big Bang vs. Phased), assemble cross-functional governance team, identify all source systems and data types, establish risk register, define rollback procedure, and obtain executive sign-off on project charter.
Output: Signed project charter with committed scope, approach, resource plan, and timeline.
Phase 2: Data Discovery and Profiling
Systematic analysis of every source system: field inventory, data type profiling, null value rates, referential integrity assessment, duplicate record identification, and value distribution analysis. Domain experts – underwriters, claims staff, actuaries – must review flagged anomalies. A claims reserve showing $0 might be a settled case or a data error. Only a claims expert knows which. This report becomes the foundation of the entire cleansing plan.
Output: Comprehensive Data Quality Report categorizing all issues by type, severity, and volume
Phase 3: Data Mapping and Transformation Design
Field-by-field source-to-target mapping covering transformation logic, cleansing rules, derivation logic, and load sequencing to preserve referential integrity (customers before policies, policies before claims, claims before line items). Peer review by IT, business, and compliance stakeholders is mandatory before any build work begins. Errors found here cost hours. Errors found during UAT cost weeks.
Output: Approved data mapping and transformation specification.
Phase 4: Infrastructure and Tooling Setup
Provisioning of development, UAT, and production environments. ETL tooling configuration, staging database design, PII masking for all non-production environments, security controls, audit logging, and full source system backup with integrity verification. No live customer PII in development or UAT. Ever.
Output: Validated migration environments with confirmed connectivity
Phase 5: Data Extraction and Cleansing
Iterative extraction begins with a representative sample of 10–20% of records. Automated cleansing rule execution, Tier 1 (blocking) defect resolution, and ongoing maintenance of the migration issue log. This log is the audit trail that regulators will ask for, and that business sign-off depends on. Tier 1 issues must be resolved before loading begins. Tier 2 and 3 issues require formal exception approval from the business.
Output: Cleansed, staged dataset with documented issue log.
Phase 6: Loading and Transformation Execution
ETL pipeline execution through development, UAT, and production environments, with a full reconciliation suite at each iteration: source vs. staging vs. target record counts and key financial aggregates must balance. Rejected records require investigation, root cause analysis, fixing, and reprocessing. A first UAT load rejection rate above 5% is a clear signal that upstream cleansing is incomplete.
Output: Loaded target system with rejection rate at or below 1% threshold.
Phase 7: Testing and Validation
Reconciliation testing (count and aggregate matching), data accuracy testing (5–10% manual spot-check of migrated records against source), System Integration Testing across affected business workflows, User Acceptance Testing with active business participation, and performance testing. UAT sign-off is a hard gate to go-live. No technical validation substitutes for business users confirming that the data works in their actual workflows.
Output: Formal written UAT sign-off from business owners.
Phase 8: Compliance and Regulatory Review
Data privacy compliance verification (GDPR/HIPAA/local regulation), data retention schedule validation, security posture review, and audit trail completeness confirmation. This documentation becomes part of the regulatory evidence package and must be retained according to the insurer’s document retention policy.
Output: Compliance documentation package including data lineage maps, audit logs, and compliance attestations.
Phase 9: Go-Live and Cutover
Legacy system freeze, final production extract, production migration load, post-load reconciliation, go-live sign-off from all required stakeholders, and cutover of all users and system integrations to the target platform. Schedule the cutover window during the lowest-volume period available – typically a weekend outside major renewal periods. Run intensive post-go-live monitoring for a minimum of 48–72 hours. The rollback trigger criteria agreed in Phase 1 must be operative throughout the entire window.
Output: Production system live; legacy in read-only mode
Phase 10: Post-Migration and Closure
The migration doesn’t end at go-live. A structured hypercare period of 30–90 days follows, during which the team remains available to resolve data issues; the legacy system remains accessible for reference, and a post-migration data quality audit is conducted. Legacy system decommissioning only happens after this period closes, and all stakeholders confirm they no longer need the legacy data in its live form. The project formally closes with a lessons-learned retrospective – one of the most valuable and consistently skipped steps in the entire process.
Output: Closed project; archived documentation; operational data governance in place.
To support everything covered in this blog, we’ve built a comprehensive Excel checklist covering all 10 migration phases, with over 85 individual tasks, each with columns for Owner, Target Date, Status, Priority, and Notes. The workbook also includes a pre-populated Risk Register with the top 10 insurance migration risks scored by likelihood and impact, and a Progress Dashboard that summarizes completion by phase.
Download the Insurance Data Migration Checklist Below – Insurance_Data_Migration_Checklist.xlsx

Choosing the Right Migration Partner: What to Look For
For most insurance organizations, migration capability is sourced externally. Vendor selection is one of the highest-leverage decisions in the programme – and it is made poorly more often than not, evaluated primarily on price and general credentials rather than the specific combination of capabilities that insurance data migration actually requires.
The right vendor must be strong across all three domains simultaneously:
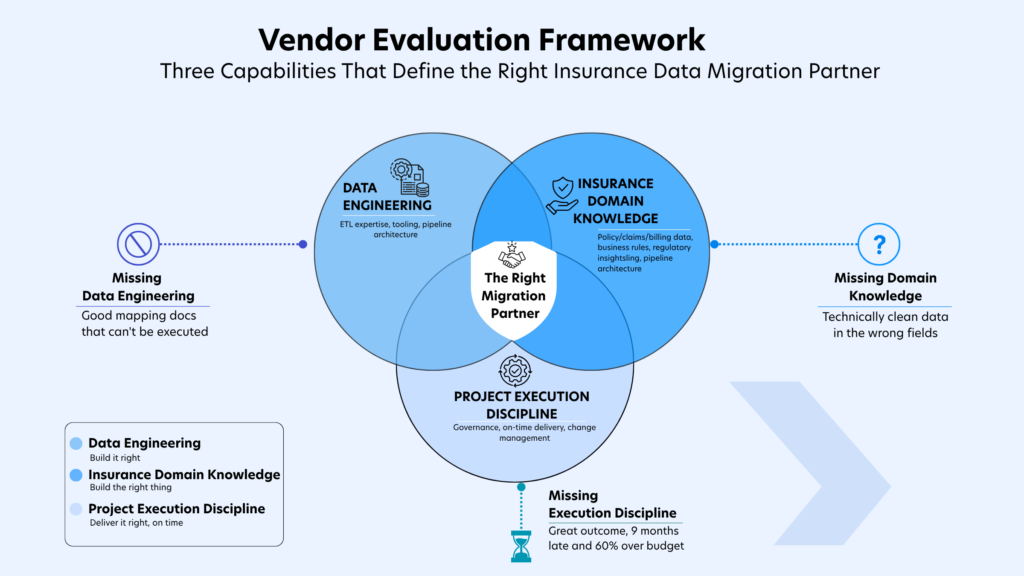
Domain 1: Data Engineering Capability
The technical foundation of migration execution is the team’s ability to profile, cleanse, transform, and load large volumes of complex data accurately. Evaluation criteria include: ETL tooling expertise and the availability of proprietary insurance-specific migration accelerators; demonstrated capability in staging-based migration architectures; built-in reconciliation framework maturity; and the team’s track record with high-volume, high-complexity data loads. Proprietary frameworks with pre-built mapping templates for common insurance legacy systems (DB2, COBOL-based mainframes, legacy policy administration platforms) represent genuine delivery acceleration when validated against the specific source architecture in scope.
Domain 2: Insurance Domain Knowledge
Technical data engineering applied without insurance domain knowledge produces migrations that are structurally complete but operationally incorrect. The vendor’s team must include practitioners with direct experience in insurance data structures: policy hierarchies, claims processing logic, billing cycle data, endorsement sequencing, and actuarial reserve methodology. Absence of this knowledge manifests as business rule mapping failures that are typically discovered during UAT – at significant cost to the project timeline.
Domain 3: Project Execution Discipline
Delivery performance in prior comparable engagements is the most reliable predictor of delivery performance in the current one. Evaluation should specifically seek: on-time and within-budget delivery rates for migrations of comparable scale; evidence of structured phase gate governance with formal sign-off requirements; escalation processes for mid-migration data quality discoveries; and the vendor’s approach to cutover planning and rollback rehearsal. Engagements structured as open-ended time-and-materials arrangements without phase gate governance are statistically more likely to overrun.
Missing even one creates risk:
- Clean pipelines, wrong data
- Perfect mappings, poor execution
- Or successful outcomes – delivered too late and over budget
This is where partners like Everforth Quinnox differentiate – by combining all three into a single, integrated delivery model tailored for insurance.
See a real-world example of all three domains in practice.
How Everforth Quinnox delivered an AI-powered insurance data integration transformation – with faster timelines, higher accuracy, and measurable business outcomes.
Conclusion
Insurance data migration is no longer optional; it’s a strategic necessity driven by legacy constraints, regulatory pressure, and the need for data-driven capabilities. The real question isn’t whether to migrate, but how to do it without disrupting operations or compromising data integrity.
The pattern is clear. Most migration failures are not caused by technology, but by preventable gaps – delayed data quality assessment, missing business rule mapping, weak governance, and untested rollback strategies. Organizations that address these early, with a structured and disciplined approach, consistently deliver better outcomes.
But methodology alone isn’t enough. What ultimately determines success is the combination of the right expertise, the right tools, and the ability to execute under real-world complexity.
That’s where Everforth Quinnox comes in. With 250+ AI and data specialists, 70+ real-world AI use cases, and 50+ enterprise accelerators, Everforth Quinnox’s QAI Studio is built specifically to handle the realities of insurance data migration – not just in theory, but in execution.
- AI-driven data profiling continuously identifies issues before they become blockers
- Predictive risk mitigation flags failure points early, reducing cutover risk
- An insurance-native migration framework ensures business rules, compliance, and data structures are handled correctly
- End-to-end automation minimizes manual effort, reducing both cost and human error
- A zero-disruption architecture keeps core operations running throughout migration
- And critically, post-migration data governance ensures data stays clean long after go-live
The result isn’t just a completed migration – it’s a future-ready data foundation that supports AI-driven underwriting, smarter claims processing, and real-time decision-making.
So, are you ready to discuss your migration program with us? Get in touch with our team today!

Lead, Marketing, Everforth Quinnox
FAQ’s Related to Insurance Data Migration
Insurance data migration is the process of transferring data from legacy systems – such as policy administration platforms, claims engines, and billing systems – to modern or cloud-based platforms while ensuring data accuracy, completeness, regulatory compliance, and business continuity throughout the transition.
The majority of failures are not caused by technical complexity alone. The five most common root causes are: deferred data quality assessment, incomplete business rule documentation, insufficient cross-functional governance, misaligned migration strategy (Big Bang vs. Phased), and untested rollback procedures. All five are preventable with structured planning.
Data migration is essential because legacy systems limit scalability, analytics, and digital capabilities. Without migration, insurers struggle to adopt AI, improve customer experience, and meet evolving regulatory requirements.
Data migration focuses on moving existing data from one system to another with accuracy and integrity. Modernization is a broader transformation – it includes redesigning business processes, replacing technology infrastructure, and retraining staff. Migration is frequently a component of a modernization programme, but the two require different governance structures, timelines, and executive sponsorship.
Not all data needs to migrate to the new production system. Many insurers apply a selective migration strategy: active policies, open claims, current customer records, and recent transactions migrate to the live system. Historical data that is rarely accessed for operations – but required for regulatory compliance – can be archived in a governed repository. This approach reduces migration complexity, improves target system performance, and shortens timelines without compromising compliance obligations.
Timelines vary significantly based on data volume, system complexity, the number of source systems, and data quality. A focused single-system migration might complete in 4–6 months. A complex multi-system migration across multiple lines of business typically runs 12–24 months. Teams that skip data profiling early consistently find their timelines extending past initial estimates during the execution phase.