AI is not just another workload. It demands high-performance computing, elastic storage, distributed data pipelines, specialized hardware, robust MLOps practices, and governance frameworks that satisfy regulatory and ethical standards. Traditional IT architectures designed primarily for transactional systems and predictable workloads often struggle to support the dynamic, data-intensive, and iterative nature of AI development and deployment.
The result? Delays, duplicated efforts, underutilized resources, and AI initiatives that fail to scale beyond proof of concept.
This is why enterprises need a clear framework that helps organizations move beyond ad hoc experimentation and toward intentional design – balancing performance, scalability, cost efficiency, security, and governance. It aligns technical decisions with business strategy, ensuring that infrastructure investments directly support AI outcomes.
This blog breaks down AI infrastructure architecture from a practical, enterprise lens. We’ll go beyond textbook definitions to explore core principles, components, deployment models, and real-world design considerations and help you design AI infrastructure that actually works.

What Is AI Infrastructure Architecture?
AI infrastructure architecture is the end-to-end platform design that enables artificial intelligence systems to move reliably from data to decision at enterprise scale. It encompasses data pipelines, compute resources, model development environments, deployment mechanisms, monitoring frameworks, and AI governance controls – working together as a cohesive system.
Unlike traditional application infrastructure, AI infrastructure must support:
In a BFSI context, this might mean processing millions of transactions per second for fraud detection. In retail, it could involve real-time personalization across digital and physical channels. In manufacturing, AI infrastructure supports predictive maintenance and computer vision on the shop floor.
What makes AI infrastructure architecture unique is its feedback-driven nature. Models influence business decisions, those decisions generate new data, and that data must flow back into training pipelines. Infrastructure must therefore be adaptive, automated, and observable by design.
Key Principles of AI Infrastructure Architecture
A well-designed AI infrastructure architecture is guided by a few core principles that distinguish scalable, production-ready systems from fragile experiments.
Key architectural components include:

- It starts with scalability by design. AI workloads are never static. Data volumes expand continuously, models grow more complex, and usage patterns fluctuate based on business demand. Infrastructure, therefore, must be elastic by default – scaling horizontally and vertically without repeated redesign. Elastic compute for training, auto-scaling inference services, and distributed data processing are not optimizations; they are foundational requirements.
- Scalability, however, quickly breaks down without separation of concerns. When training jobs, real-time inference, experimentation, and monitoring compete for the same resources, performance becomes unpredictable, and teams lose control. Decoupling these workloads allows each layer to scale independently – training can surge without impacting customer-facing inference, and experimentation can continue without destabilizing production systems.
- Once workloads are properly separated, automation becomes a force multiplier. Manual provisioning, deployment, and monitoring simply cannot keep pace with AI’s rate of change. Mature AI platforms embed automation across the lifecycle – CI/CD pipelines for models, automated retraining triggered by drift, and policy-driven governance that enforces standards without slowing teams down. This is where MLOps evolves from a tooling concept into a platform capability.
- Automation alone is not sufficient without resilience and fault tolerance. AI systems are long-running, data-dependent, and often mission-critical. Data pipelines fail, training jobs crash, and models occasionally behave unexpectedly. Well-architected infrastructure anticipates these failures, isolates them, and degrades gracefully – preventing localized issues from cascading into enterprise-wide outages.
- All of these principles ultimately converge on cost awareness. AI infrastructure can become expensive faster than almost any other enterprise workload, particularly with GPU-intensive training and always-on inference services. Intelligent resource scheduling, workload prioritization, and continuous usage monitoring ensure that scalability and resilience do not come at the expense of financial discipline. In mature architectures, cost is treated as a design parameter – not an afterthought.
Together, these principles define AI infrastructure that behaves like software: scalable, modular, automated, resilient, and economically optimized. This interconnected design mindset is what enables enterprises to move from fragile AI pilots to dependable, outcome-driven platforms.
Core Components of AI Infrastructure Architecture
AI infrastructure architecture is best understood by examining its core building blocks, each serving a distinct role in the AI lifecycle.
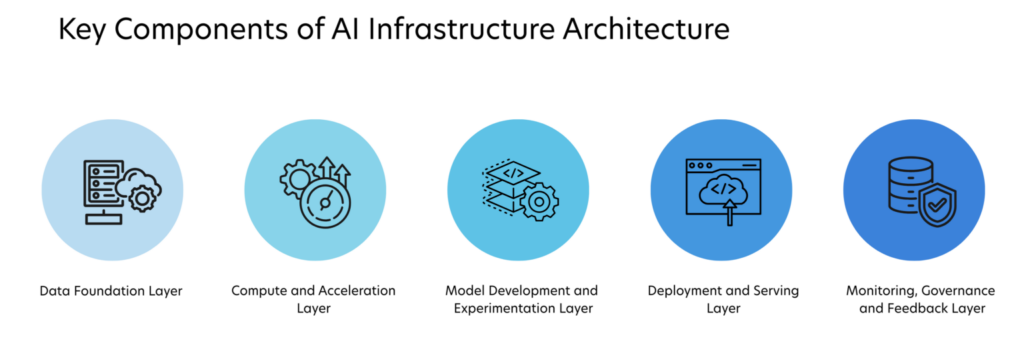
- The Data Foundation Layer forms the foundation. This includes data sources (transactional systems, IoT devices, logs, third-party feeds), ingestion pipelines, and storage systems such as data lakes and warehouses. The architecture must support both batch and streaming data, along with data versioning and lineage to ensure reproducibility.
- The Compute and Acceleration Layer, which powers training and inference. Training workloads often rely on GPUs, TPUs, or high-performance CPUs, while inference may use optimized CPU or GPU instances depending on latency requirements. Distributed computing frameworks are commonly used to parallelize workloads.
- The Model Development and Experimentation Layer provides tools and environments for data scientists and ML engineers. This includes notebooks, experimentation platforms, feature stores, and training orchestration systems. Reproducibility, experiment tracking, and collaboration are key requirements here.
Stat to Note: According to Stanford AI Index Research, AI model training time has been reduced by 80% in the last five years due to advancements in distributed computing.
- The Deployment and Serving Layer is where AI meets the real world. Models are packaged, versioned, and deployed as APIs or embedded services. This layer must support blue-green deployments, canary testing, and rollback mechanisms to minimize risk.
- The Monitoring, Governance, and Feedback Layer closes the loop. AI systems must be monitored not only for infrastructure metrics like latency and uptime, but also for model-specific indicators such as accuracy, bias, and drift. Feedback from production feeds back into retraining pipelines, enabling continuous improvement.
How to Choose the Right AI Infrastructure Architecture
Selecting the right AI infrastructure architecture is not a purely technical decision. It is a strategic choice that must align with business priorities, regulatory constraints, data characteristics, and long-term operating models.
Organizations that treat architecture selection as a checklist of tools often end up with fragmented platforms, escalating costs, and stalled production adoption. Those that approach it as a structured decision process build infrastructure that scales with both technology and business ambition.
1. Start with business outcomes and AI maturity
The most effective architecture decisions begin with clarity on what the organization is trying to achieve with AI. Real-time fraud detection, conversational assistants, predictive maintenance, and generative content platforms all impose very different infrastructure requirements.
Equally important is the organization’s AI maturity level. Early-stage teams benefit from managed services and cloud native experimentation environments that minimize operational overhead. Mature enterprises with stable workloads, strict governance needs, or large-scale data gravity may justify hybrid or on-premises investments.
Architecture should evolve with maturity rather than attempting to optimize a distant future state on day one.
2. Evaluate data gravity, sensitivity, and movement
Data characteristics often determine architecture more than model complexity.
Key questions include:
- Where does the majority of enterprise data currently reside
- How sensitive or regulated is that data
- How frequently must data move between systems
- Whether real time processing is required or batch processing is sufficient
Highly regulated or latency-sensitive environments often favor localized or hybrid compute near the data source. Exploratory analytics, large-scale training, and burst experimentation typically benefit from elastic cloud resources. Minimizing unnecessary data movement reduces cost, latency, and compliance risk simultaneously.
3. Match compute strategy to workload patterns
AI workloads are inherently uneven. Training jobs are bursty and compute intensive, while inference workloads demand consistent low latency availability.
Choosing the right architecture requires understanding:
- Frequency and duration of training cycles
- Scale and concurrency of inference requests
- Hardware acceleration needs such as GPUs or specialized processors
- Tolerance for cold starts or provisioning delays
Cloud elasticity is well-suited for unpredictable or rapidly growing workloads. Dedicated infrastructure becomes economical when utilization is consistently high and predictable. Hybrid strategies often deliver the best balance by separating steady inference from burst training demand.
4. Consider governance, security, and regulatory exposure early
Security and compliance constraints should shape architecture from the beginning rather than being retrofitted later. Industries such as banking, healthcare, and public sector environments must often ensure:
- Strict control over data residency
- Full traceability of model decisions
- Auditable training datasets and evaluation metrics
- Controlled external model or API usage
If governance requirements are stringent, architectures that keep sensitive data and core inference within controlled environments while using external compute selectively tend to provide the safest path forward.
5. Optimize for operating model, not just technology
Long term success depends less on which platform is chosen and more on how easily teams can build, deploy, monitor, and evolve AI systems within it.
Decision makers should evaluate:
- Availability of internal platform engineering and MLOps expertise
- Integration with existing DevOps, data, and security workflows
- Vendor lock in risk and portability of models and data
- Total cost of ownership across infrastructure, operations, and talent
An architecture that is slightly less optimized technically but significantly easier to operate often delivers greater real-world value.
Best Practices for Designing AI Infrastructure Architecture
- Successful AI infrastructure design starts with business alignment. Infrastructure should be designed around use cases and outcomes, not tools or trends.
- Adopting a modular and composable architecture allows teams to evolve components independently. This reduces vendor lock-in and future-proofs the platform.
- Investing early in MLOps and automation pays long-term dividends. Automated pipelines reduce errors, speed up deployment, and improve reliability.
- Equally important is cross-functional collaboration. AI infrastructure sits at the intersection of data science, engineering, security, and operations. Strong governance and shared ownership prevent silos.
- Finally, treat AI infrastructure as a living system. Continuous monitoring, optimization, and iteration are essential as models, data, and business needs evolve.
Build Your Foundation for Scalable and Trusted AI Infrastructure Architecture with Quinnox
AI infrastructure architecture is the difference between AI ambition and AI reality. While models may capture headlines, infrastructure determines whether those models deliver consistent, scalable, and trustworthy outcomes.
As enterprises move toward more autonomous, real-time, and generative AI systems, the conversation is also shifting toward Quality AI that emphasizes reliability, governance, observability, and measurable business value alongside model performance. Reaching this level of maturity requires infrastructure designed for traceability, resilience, and continuous learning across the full data-to-decision lifecycle.
This is where Quinnox AI (QAI) Studio plays a transformative role. Backed by a deep bench of AI and data specialists, proven enterprise implementations, and a rich library of ready-to-deploy accelerators, the platform enables organizations to bypass common infrastructure complexity. From early experimentation to enterprise scale rollout, its pre-engineered and scalable environments allow teams to concentrate on innovation and business impact rather than platform setup and operational overhead.
Get in touch with QAI Studio today and turn your AI ambitions into reality!

Lead, Marketing, Quinnox
FAQs Related to AI Infrastructure Architecture
AI infrastructure is designed for data-intensive, compute-heavy, and continuously evolving workloads. Unlike traditional IT, it must support large-scale data pipelines, bursty model training, low-latency inference, and continuous retraining – while also managing model drift, governance, and automation through MLOps.
Cost and performance are balanced by separating workloads, right-sizing compute, and automating resource allocation. Elastic scaling, intelligent GPU scheduling, and usage-based monitoring ensure high performance for critical workloads without over-provisioning or uncontrolled spend.
The most common challenges include scaling from pilot to production, managing rising infrastructure costs, ensuring data security and compliance, integrating with legacy systems, and operationalizing models reliably through automation and governance.
There is no one-size-fits-all answer. Cloud offers speed and flexibility, on-prem provides control and predictability, and hybrid architectures deliver the best balance for most enterprises—combining innovation, scalability, and regulatory compliance.
As AI use cases scale, infrastructure evolves from isolated environments to shared platforms with standardized pipelines, automated MLOps, stronger governance, and outcome-driven optimization. The focus shifts from experimentation to reliability, efficiency, and enterprise-wide impact.